Reinforcement Learningについて体系的学習
テキストは「Pythonde学ぶ強化学習、著:久保孝宏」
——————————————-
急に難解になってきたぞ!
——————————————-
まずは、コイントスにおけるEpsilon-Greedy法
実行してみると、Mac OS Xだといきなりnumpyエラー: Users/****/.cond/envs/rlbook/lib/python3.6/site-pkgs/numpyフォルダを消去して、再度、pip install numpyでエラー脱出。
——————————————-
epsilon-greedy.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
if __name__ == "__main__": import pandas as pd import matplotlib.pyplot as plt def main(): env = CoinToss([0.1, 0.5, 0.1, 0.9, 0.1]) #head_probsに収められる5枚の各コインの表のでる確率 epsilons = [0.0, 0.1, 0.2, 0.5, 0.8] #epsilon係数:探索行動の比率:5通りを設定 game_steps = list(range(10, 310, 10)) result = {} for e in epsilons: # epsilonsの回数繰り返す。 agent = EpsilonGreedyAgent(epsilon=e) #エージェントを係数とともに指定 means = [] #means配列確保 for s in game_steps: #レンジ10〜310を10刻みで繰り返す. env.max_episode_steps = s #CoinTossクラスのインスタンスenvにmax_episode_stepsを順に指定 rewards = agent.play(env) #EpsilonGreedyAgentのインスタンスagentにplay()、返り値のrewardsを得る。 means.append(np.mean(rewards)) #rewards平均値を配列meansへ収める. result["epsilon={}".format(e)] = means #epsilon=0.1を表記 result["coin toss count"] = game_steps result = pd.DataFrame(result) result.set_index("coin toss count", drop=True, inplace=True) result.plot.line(figsize=(10, 5)) plt.show() main() |
CoinTossクラスを読んで見る。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
class CoinToss(): def __init__(self, head_probs, max_episode_steps=30): self.head_probs = head_probs #コインの表の確率配列 self.max_episode_steps = max_episode_steps #コイントス繰り返し数設定 self.toss_count = 0 #toss_countを0へ def __len__(self): return len(self.head_probs) #コインの枚数 def reset(self): self.toss_count = 0 def step(self, action): #コイントス, actionはコインの選択行動 final = self.max_episode_steps - 1 if self.toss_count > final: #toss_countが30回に到達すれば終了 raise Exception("The step count exceeded maximum. \ Please reset env.") else: done = True if self.toss_count == final else False if action >= len(self.head_probs): raise Exception("The No.{} coin doesn't exist.".format(action)) else: head_prob = self.head_probs[action] #actionで選択されたコインに対して表確率を得る if random.random() < head_prob: #表確率より小さな数字であればコインで表が出たとして報酬1点取得。 reward = 1.0 else: reward = 0.0 #コインで裏が出れば報酬なし self.toss_count += 1 return reward, done #報酬を返す |
Epsilon−Greedy法に基づいて行動するAgentクラス
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
class EpsilonGreedyAgent(): def __init__(self, epsilon): self.epsilon = epsilon self.V = [] #コインのトス結果に基づく期待値を保持する配列 def policy(self): coins = range(len(self.V)) if random.random() < self.epsilon: return random.choice(coins) #コインの選択 else: return np.argmax(self.V) def play(self, env): # Initialize estimation. N = [0] * len(env) self.V = [0] * len(env) env.reset() done = False rewards = [] while not done: selected_coin = self.policy() #ポリシーによるコインの選択 reward, done = env.step(selected_coin) #選択されたコインに対して、CoinTossのインスタンスenvに対してstep()関数でコイントス行動. rewardが返される。 rewards.append(reward) #rewardを配列rewardsへ収める n = N[selected_coin] coin_average = self.V[selected_coin] #コインの期待値を収める new_average = (coin_average * n + reward) / (n + 1) N[selected_coin] += 1 self.V[selected_coin] = new_average return rewards |
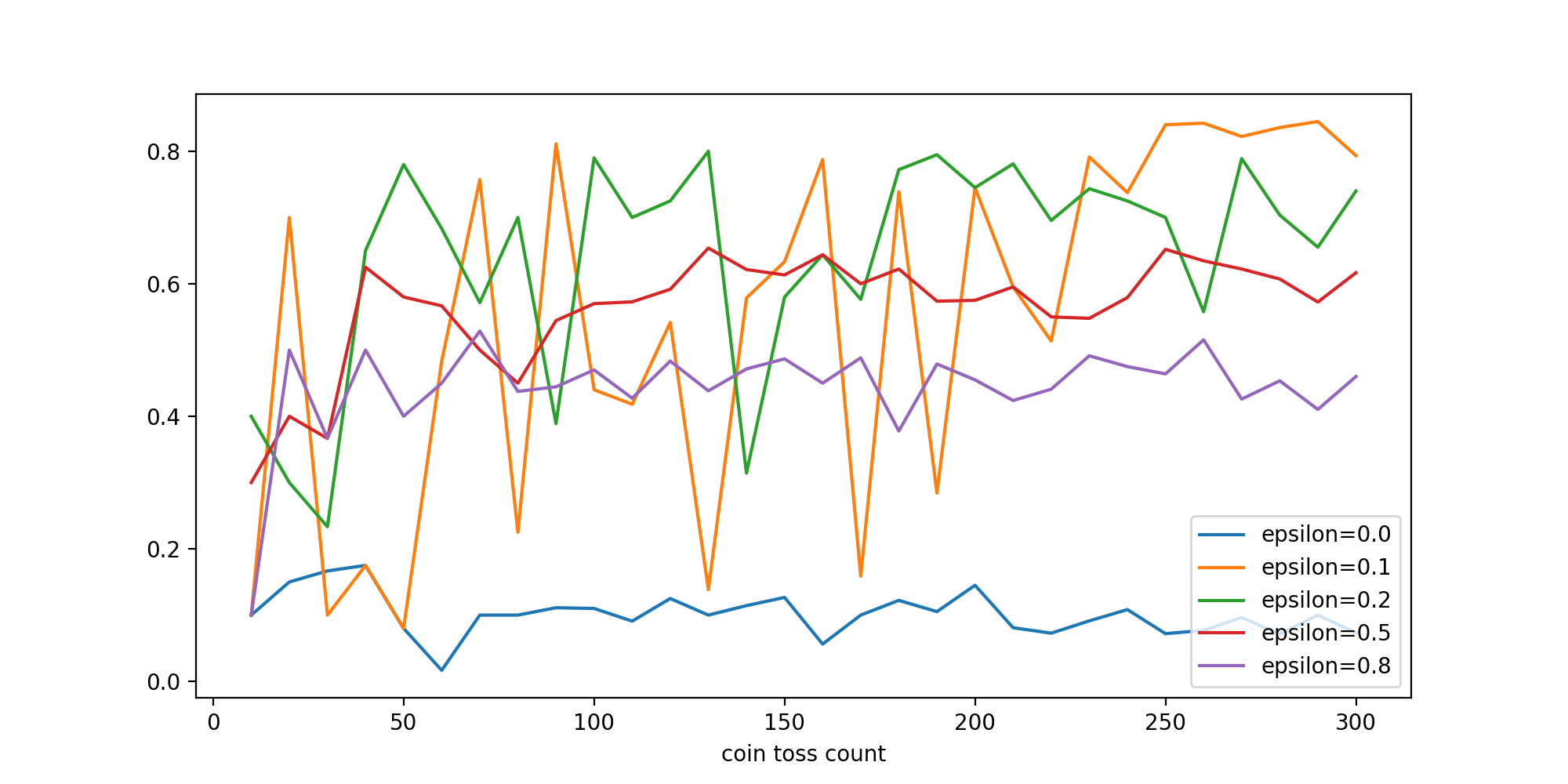
このあと、いろいろな方法が示されて、Actor Critic法へたどり着く(省略)。