Reinforcement Learningについて体系的学習
テキストは「Pythonde学ぶ強化学習、著:久保孝宏」
——————————————-
時刻tにおける状態stの状態価値Vπ(st)を、「状態stを起点に、方策πに従って行動をとり続けて行った時の報酬の合計(すなわち)収益」と定義。
Vπ(st)=rt+1+γVπ(st+1)
つまり、ある時刻における価値関数は、その先の時刻における価値関数の漸化式になっているということ。
しかしながら、ある状態sから方策πにしたがって取る行動a(右に移動、それとも左、上、下?)は一義的に決まらない(確率分布)のである。実際には、確率分布にしたがって複数の行動候補から実際の行動が決定される。
現実の行動はどれか一つをとるが、価値関数は未来の収益を考えるため、枝分かれの全ての選択肢を考慮する必要がある。
状態sの時に戦略πに従って行動aをとったとき、それに対する結果、つまり対応する状態(s′)は一義的に決まらない(確率分布である)ために遷移確率(transition probability)を考える。行動a(右)を取ろうとしたのに、結果的に下に行ってしまうというのは「千鳥足状態!」。
Pass′=Pr{st+1=s′|st=s,at=a}、その際の報酬はRass′
——————————————-
状態価値関数 Vπに対するBellman方程式
価値関数は、直近の報酬に1ステップ先の価値関数を足したものである。ただし、方策および遷移確率で未来のとりうる値は枝分かれするので、その期待値をとる。
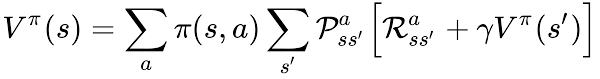
価値が最大になるように常に行動を選択する場合、戦略ではなくて、最大報酬を取ることとなり、
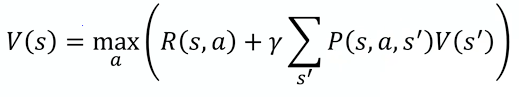
——————————————–
ともかく、bellman_equation.pyを実行してみる。main関数に出力が規程されているように
|
1 2 3 4 |
if __name__ == "__main__": print(V("state")) print(V("state_up_up")) print(V("state_down_down")) |
であれば、その価値は、
|
1 2 3 4 |
(rl-book) MacBook-Pro-6:DP $ python bellman_equation.py 0.7880942034605892 0.9068026334400001 -0.96059601 |
なんのこっちゃ、だけど、つまりstate=はじめの状態では、価値は0.7881、up、up選べば、0.9068まで価値が上がるが、down、 downと選ばれれば-.9606まで下がる。5回中、upが4回以上でhappy endの報酬1点がもらえるが、それ未満だとbad endで-1点となる。つまりdownが1回以上含まれていると価値は絶望的に低下し、逆に3回以上upがあればかなお駄賃1を貰えそうということなる。
|
1 2 3 4 5 6 |
if __name__ == "__main__": print(V("state")) print(V("state_up_up_up")) print(V("state_up_up_up_donwn")) print(V("state_down_down_down")) print(V("state_down_up_down")) |
とすると、価値の結果は以下の通り
|
1 2 3 4 5 6 |
(rl-book) MacBook-Pro-6:DP $ python bellman_equation.py 0.7880942034605892 0.9508930200000001 0.78408 -0.9702989999999999 -0.9702989999999999 |
——————————————–
実際には、Valueベースの方法では、価値を予め計算して、そのうちから最大のものを選択する必要がある。つまり、価値の計算が済みである必要があり、状態数が多いと非現実的となってくる。そこで動的計画法Dynamic Programming:DPでは適当なV(s’)を選択して、複数回、計算を繰り返す価値反復法Value Iterationで精度を上げる方法を取る。
精度については、更新前後の差(|Vi+1(s)-Vi(s)|)が一定値より小さいかで判定する。
Day2の最後は、Dynamic Programming Simulatorを仮想環境で作動させる。
|
1 2 |
(rl-book) MacBook-Pro-6:DP $ python run_server.py Run server on port: 8888 |
