Reinforcement Learningについて体系的に学習しておきたい。
テキストは「Pythonde学ぶ強化学習、著:久保孝宏」
——————————————-
強化学習とは?
強化学習と、機械学習、人工知能といったキーワードの関係を理解する
強化学習以外の学習法に対する、強化学習のメリット・デメリットを理解する
機械学習の基本的な仕組みを理解する
——————————————-
Markov Decision Process(MDP)マルコフ決定過程の構成要素
s: 状態(State)
a: 行動(Action)
T:状態遷移の確率(遷移関数/Transition function)
R:即時報酬(報酬関数/Reward function)
ここで行動の主体が具現化したものであるならばロボットのようなものであるが、プログラム的には状態を受け取り、行動を出力する関数であり、この関数を戦略Policyと呼ぶ。この戦略に従って動く行動の主体をエージェントAgentと呼ぶ。
MDPにおける報酬(r)は「直前の状態と遷移先」に依存する即時報酬immediate rewardである。
即時報酬だけを得るようにしても、エピソードにおける報酬の総和を最大化することはできない。
報酬の総和は、エピソードがT時刻に終了するとして、
Gt = r(t+1) + r(t+2) + …..+ r(T) と記述できるが、これはエピソード終了時点でないと計算できない。
そこで「見積もり」を立てることになる。でも見積もりは不正確なので、その分を割り引いて考える必要がある。この割り引くための係数を割引率(Discount factor)γと呼ぶ。
割引率を含んだ報酬の総和は、
Gt = r(t+1) + γr(t+2) + γ^2(r(t+3) +…..+ γ^(T-t-1)r(T)
割引率は0から1の間であり、将来になればなるほど、割引率の指数が増加し、割り引かれていく。
先のことはどうなるかわからないからである。即時報酬を将来の不確からしさを割り引いて計算したものは現時点での「割引現在価値」と呼ばれる。
再帰的な表現では、
Gt = r(t+1) + γG(t+1)
ここでGtは、報酬の総和を見積もった「期待報酬Expected reward」、あるいは「価値Value」と呼ぶ。
価値を算出することを「価値評価Value approximation」と呼ぶ。
この価値評価が、強化学習が学習する2つのことの一点目である「行動の評価方法」となる。
行動の評価は、行動自体や行動の結果、遷移する状態の価値評価によって行われる。
——————————————
コメント;まるで、不動産屋の講習会のようだね。強化学習=不動産屋=トランプ流か!
——————————————
とりあえず、デモ environment_demo.py を動かしてみる。
|
1 2 3 4 5 6 7 8 9 10 11 |
(rl-book) MacBook-Pro-6:DP $ python environment_demo.py Episode 0: Agent gets -1.6 reward. Episode 1: Agent gets -1.28 reward. Episode 2: Agent gets -4.680000000000002 reward. Episode 3: Agent gets -1.200000000000001 reward. Episode 4: Agent gets -1.32 reward. Episode 5: Agent gets -2.120000000000002 reward. Episode 6: Agent gets -3.9200000000000017 reward. Episode 7: Agent gets -2.6400000000000006 reward. Episode 8: Agent gets 0.72 reward. Episode 9: Agent gets -1.8800000000000003 reward. |
なるほど、10回トライして、報酬総和を算出している。Agentの行動の経過がわからないので、現位置表示print(state) をmain関数のwhile not doneのループ内に記述する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
while not done: action = agent.policy(state) print(state) #追加1:現位置表示 next_state, reward, done = env.step(action) total_reward += reward print("Reward: {} Total Reward: {}".format(reward, total_reward)) #追加1:行動結果で得られた報酬と報酬総和表示 state = next_state print("Episode {}: Agent gets {} reward.".format(i, total_reward)) while not done: action = agent.policy(state) next_state, reward, done = env.step(action) total_reward += reward state = next_state print("Episode {}: Agent gets {} reward.".format(i, total_reward)) |
このモデルの環境の座標位置と報酬について、エクセルで整理してみる。
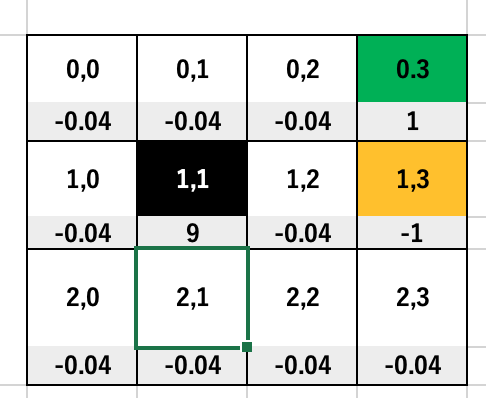
スタート地点の座標は[2,0]で、そこから、そのままま[2,0]に留まって、-0.04の減点、
次に、[2,1]の右横に移動して、-0.04の減点と続く。最後手前、[0,2]の位置にたどり着いて、右横に移動して、
[0,3]となって1点を獲得し、総合報酬は、-1.840と借金状態。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 |
(rl-book) MacBook-Pro-6:DP $ python environment_demo.py <State: [2, 0]> Reward: -0.04 Total Reward: -0.04 <State: [2, 0]> Reward: -0.04 Total Reward: -0.08 <State: [2, 1]> Reward: -0.04 Total Reward: -0.12 <State: [2, 1]> Reward: -0.04 Total Reward: -0.16 <State: [2, 2]> Reward: -0.04 Total Reward: -0.2 <State: [2, 1]> Reward: -0.04 Total Reward: -0.24000000000000002 <State: [2, 1]> Reward: -0.04 Total Reward: -0.28 <State: [2, 0]> Reward: -0.04 Total Reward: -0.32 <State: [1, 0]> Reward: -0.04 Total Reward: -0.36 <State: [1, 0]> Reward: -0.04 Total Reward: -0.39999999999999997 <State: [0, 0]> Reward: -0.04 Total Reward: -0.43999999999999995 <State: [0, 0]> Reward: -0.04 Total Reward: -0.4799999999999999 <State: [1, 0]> Reward: -0.04 Total Reward: -0.5199999999999999 <State: [2, 0]> Reward: -0.04 Total Reward: -0.5599999999999999 <State: [2, 0]> Reward: -0.04 Total Reward: -0.6 <State: [2, 1]> Reward: -0.04 Total Reward: -0.64 <State: [2, 0]> Reward: -0.04 Total Reward: -0.68 <State: [2, 0]> Reward: -0.04 Total Reward: -0.7200000000000001 <State: [2, 0]> Reward: -0.04 Total Reward: -0.7600000000000001 <State: [1, 0]> Reward: -0.04 Total Reward: -0.8000000000000002 <State: [0, 0]> Reward: -0.04 Total Reward: -0.8400000000000002 <State: [0, 0]> Reward: -0.04 Total Reward: -0.8800000000000002 <State: [0, 1]> Reward: -0.04 Total Reward: -0.9200000000000003 <State: [0, 1]> Reward: -0.04 Total Reward: -0.9600000000000003 <State: [0, 0]> Reward: -0.04 Total Reward: -1.0000000000000002 <State: [0, 0]> Reward: -0.04 Total Reward: -1.0400000000000003 <State: [0, 1]> Reward: -0.04 Total Reward: -1.0800000000000003 <State: [0, 0]> Reward: -0.04 Total Reward: -1.1200000000000003 <State: [0, 1]> Reward: -0.04 Total Reward: -1.1600000000000004 <State: [0, 2]> Reward: -0.04 Total Reward: -1.2000000000000004 <State: [0, 1]> Reward: -0.04 Total Reward: -1.2400000000000004 <State: [0, 0]> Reward: -0.04 Total Reward: -1.2800000000000005 <State: [0, 0]> Reward: -0.04 Total Reward: -1.3200000000000005 <State: [1, 0]> Reward: -0.04 Total Reward: -1.3600000000000005 <State: [2, 0]> Reward: -0.04 Total Reward: -1.4000000000000006 <State: [2, 1]> Reward: -0.04 Total Reward: -1.4400000000000006 <State: [2, 1]> Reward: -0.04 Total Reward: -1.4800000000000006 <State: [2, 1]> Reward: -0.04 Total Reward: -1.5200000000000007 <State: [2, 2]> Reward: -0.04 Total Reward: -1.5600000000000007 <State: [2, 1]> Reward: -0.04 Total Reward: -1.6000000000000008 <State: [2, 1]> Reward: -0.04 Total Reward: -1.6400000000000008 <State: [2, 1]> Reward: -0.04 Total Reward: -1.6800000000000008 <State: [2, 0]> Reward: -0.04 Total Reward: -1.7200000000000009 <State: [2, 0]> Reward: -0.04 Total Reward: -1.760000000000001 <State: [2, 1]> Reward: -0.04 Total Reward: -1.800000000000001 <State: [2, 0]> Reward: -0.04 Total Reward: -1.840000000000001 <State: [1, 0]> Reward: -0.04 Total Reward: -1.880000000000001 <State: [0, 0]> Reward: -0.04 Total Reward: -1.920000000000001 <State: [0, 1]> Reward: -0.04 Total Reward: -1.960000000000001 <State: [0, 0]> Reward: -0.04 Total Reward: -2.000000000000001 <State: [0, 0]> Reward: -0.04 Total Reward: -2.040000000000001 <State: [0, 0]> Reward: -0.04 Total Reward: -2.080000000000001 <State: [0, 0]> Reward: -0.04 Total Reward: -2.120000000000001 <State: [0, 0]> Reward: -0.04 Total Reward: -2.160000000000001 <State: [0, 0]> Reward: -0.04 Total Reward: -2.200000000000001 <State: [1, 0]> Reward: -0.04 Total Reward: -2.240000000000001 <State: [0, 0]> Reward: -0.04 Total Reward: -2.280000000000001 <State: [0, 1]> Reward: -0.04 Total Reward: -2.320000000000001 <State: [0, 1]> Reward: -0.04 Total Reward: -2.360000000000001 <State: [0, 0]> Reward: -0.04 Total Reward: -2.4000000000000012 <State: [0, 0]> Reward: -0.04 Total Reward: -2.4400000000000013 <State: [0, 1]> Reward: -0.04 Total Reward: -2.4800000000000013 <State: [0, 1]> Reward: -0.04 Total Reward: -2.5200000000000014 <State: [0, 2]> Reward: -0.04 Total Reward: -2.5600000000000014 <State: [0, 1]> Reward: -0.04 Total Reward: -2.6000000000000014 <State: [0, 2]> Reward: -0.04 Total Reward: -2.6400000000000015 <State: [0, 2]> Reward: -0.04 Total Reward: -2.6800000000000015 <State: [0, 1]> Reward: -0.04 Total Reward: -2.7200000000000015 <State: [0, 0]> Reward: -0.04 Total Reward: -2.7600000000000016 <State: [0, 0]> Reward: -0.04 Total Reward: -2.8000000000000016 <State: [0, 1]> Reward: -0.04 Total Reward: -2.8400000000000016 <State: [0, 2]> Reward: 1 Total Reward: -1.8400000000000016 Episode 0: Agent gets -1.8400000000000016 reward. ............... ............... ............... Episode 8: Agent gets -1.48 reward. <State: [2, 0]> Reward: -0.04 Total Reward: -0.04 <State: [2, 1]> Reward: -0.04 Total Reward: -0.08 <State: [2, 1]> Reward: -0.04 Total Reward: -0.12 <State: [2, 2]> Reward: -0.04 Total Reward: -0.16 <State: [2, 3]> Reward: -0.04 Total Reward: -0.2 <State: [2, 2]> Reward: -0.04 Total Reward: -0.24000000000000002 <State: [1, 2]> Reward: -0.04 Total Reward: -0.28 <State: [2, 2]> Reward: -0.04 Total Reward: -0.32 <State: [2, 3]> Reward: -1 Total Reward: -1.32 Episode 9: Agent gets -1.32 reward. |
最後にたどり着いた位置が表示されていないので、修正する。
|
1 2 3 4 5 6 7 8 9 10 |
while not done: action = agent.policy(state) print(state) next_state, reward, done = env.step(action) total_reward += reward print("Reward: {} Total Reward: {}".format(reward, total_reward)) state = next_state print("Fianl state:", next_state) print("Episode {}: Agent gets {} reward.".format(i, total_reward)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
(rl-book) MacBook-Pro-6:DP teijisw$ python environment_demo.py ....... ....... <State: [2, 0]> Reward: -0.04 Total Reward: -0.04 <State: [2, 0]> Reward: -0.04 Total Reward: -0.08 <State: [1, 0]> Reward: -0.04 Total Reward: -0.12 <State: [0, 0]> Reward: -0.04 Total Reward: -0.16 <State: [1, 0]> Reward: -0.04 Total Reward: -0.2 <State: [1, 0]> Reward: -0.04 Total Reward: -0.24000000000000002 <State: [1, 0]> Reward: -0.04 Total Reward: -0.28 <State: [1, 0]> Reward: -0.04 Total Reward: -0.32 <State: [2, 0]> Reward: -0.04 Total Reward: -0.36 <State: [1, 0]> Reward: -0.04 Total Reward: -0.39999999999999997 <State: [0, 0]> Reward: -0.04 Total Reward: -0.43999999999999995 <State: [0, 0]> Reward: -0.04 Total Reward: -0.4799999999999999 <State: [0, 1]> Reward: -0.04 Total Reward: -0.5199999999999999 <State: [0, 1]> Reward: -0.04 Total Reward: -0.5599999999999999 <State: [0, 0]> Reward: -0.04 Total Reward: -0.6 <State: [0, 0]> Reward: -0.04 Total Reward: -0.64 <State: [0, 1]> Reward: -0.04 Total Reward: -0.68 <State: [0, 2]> Reward: 1 Total Reward: 0.31999999999999995 Fianl state: <State: [0, 3]> Episode 8: Agent gets 0.31999999999999995 reward. <State: [2, 0]> Reward: -0.04 Total Reward: -0.04 <State: [2, 1]> Reward: -0.04 Total Reward: -0.08 <State: [2, 1]> Reward: -0.04 Total Reward: -0.12 <State: [2, 2]> Reward: -0.04 Total Reward: -0.16 <State: [2, 2]> Reward: -0.04 Total Reward: -0.2 <State: [2, 1]> Reward: -0.04 Total Reward: -0.24000000000000002 <State: [2, 2]> Reward: -0.04 Total Reward: -0.28 <State: [1, 2]> Reward: -0.04 Total Reward: -0.32 <State: [2, 2]> Reward: -0.04 Total Reward: -0.36 <State: [1, 2]> Reward: -1 Total Reward: -1.3599999999999999 Fianl state: <State: [1, 3]> Episode 9: Agent gets -1.3599999999999999 reward. |
[0,3]で終了して1点確保か、[1,3]で終了して1点を減点されるか!