M1 MacにApache Zeppelinをインストールして、Spark Interpreterを作動させようとした。Docker Imageでも、直接、起動さしてもエラーで、ちょっと諦める(Intel Macでは、Docker Imageで、Zeppelin、Spark Interpreterは快適に作動)。
そこで、Jupyter Notebookでspylon-kernelを挑戦してみる。
|
1 |
conda install -c conda-forge spylon-kernel |
Anacondaから、Jupyter Notebookを起動させると、新規で「spylon-kernel」が選択可能となった。
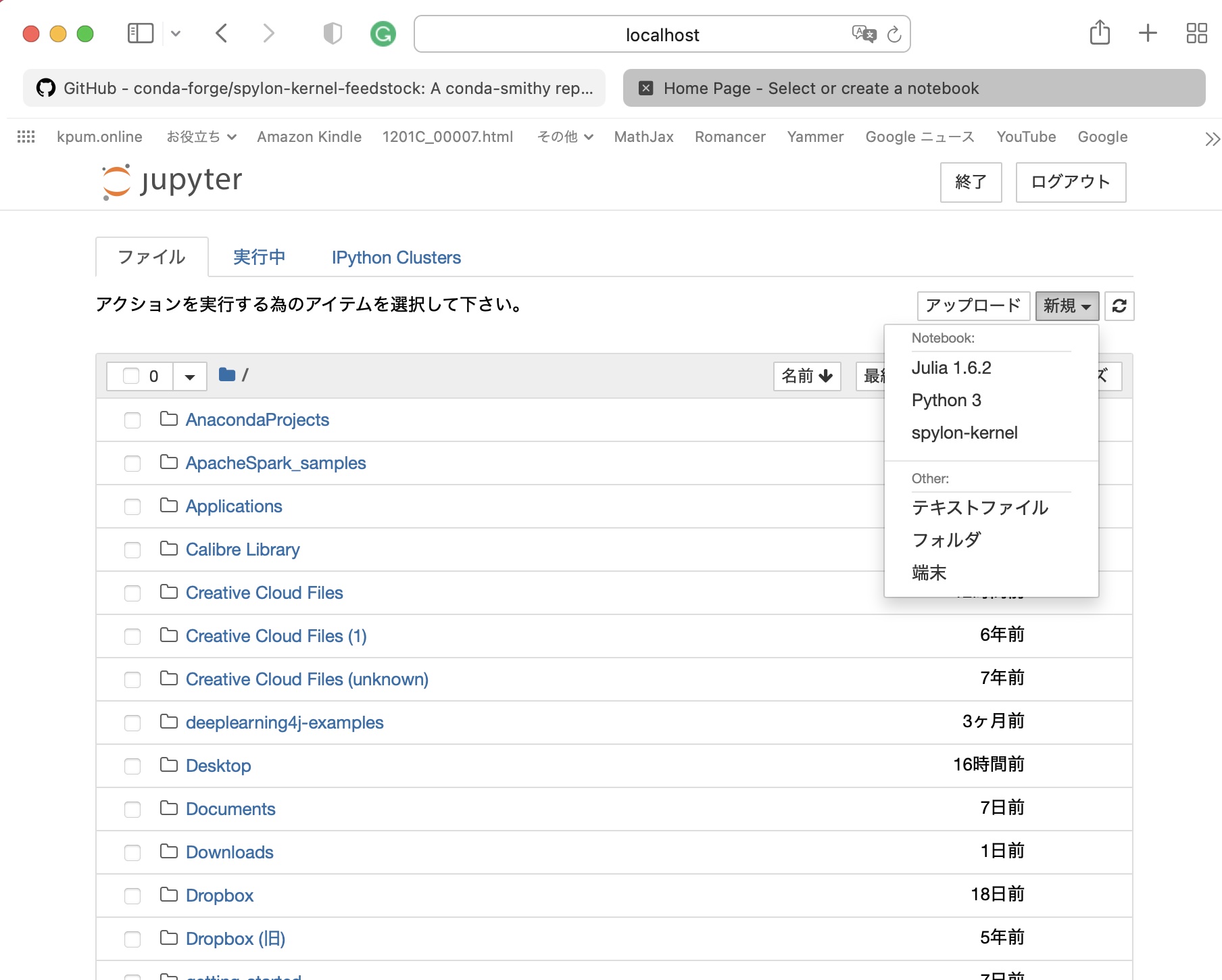
Scalaのコードを入力していく。
|
1 2 3 4 5 6 7 8 9 10 |
import org.apache.spark.ml.Pipeline import org.apache.spark.ml.feature._ import org.apache.spark.ml.classification.DecisionTreeClassifier import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics Intitializing Scala interpreter ... Spark Web UI available at http://10.21.122.61:4043 SparkContext available as 'sc' (version = 3.2.0, master = local[*], app id = local-1639785017245) SparkSession available as 'spark' |
SparkのInterpreterが無事に作動していることが確認できた。
そこで、先のブログで示したHDFSにおいたデータファイルを取り込めるか確認してみる。
|
1 2 3 4 5 6 7 8 |
val featureNames = Seq("dept", "room", "entry", "anesth", "AS", "age", "gender", "height", "weight", "BMI", "start_time", "ane_start", "surg_time", "ope_portion", "position", "pressor") val rdd = sc.textFile("hdfs://localhost:9000/linkage/data_5.csv").map(line => line.split(",")).map(v => (v(0), v(1), v(2), v(3), v(4), v(5), v(6), v(7), v(8), v(9), v(10), v(11), v(12), v(13), v(14), v(15))) val _df = rdd.toDF(featureNames: _*) _df.head() res0: org.apache.spark.sql.Row = [15,11,1,2,2,60,0,170.5,63.6,21.88,8,9,720,24,5,TRUE] |
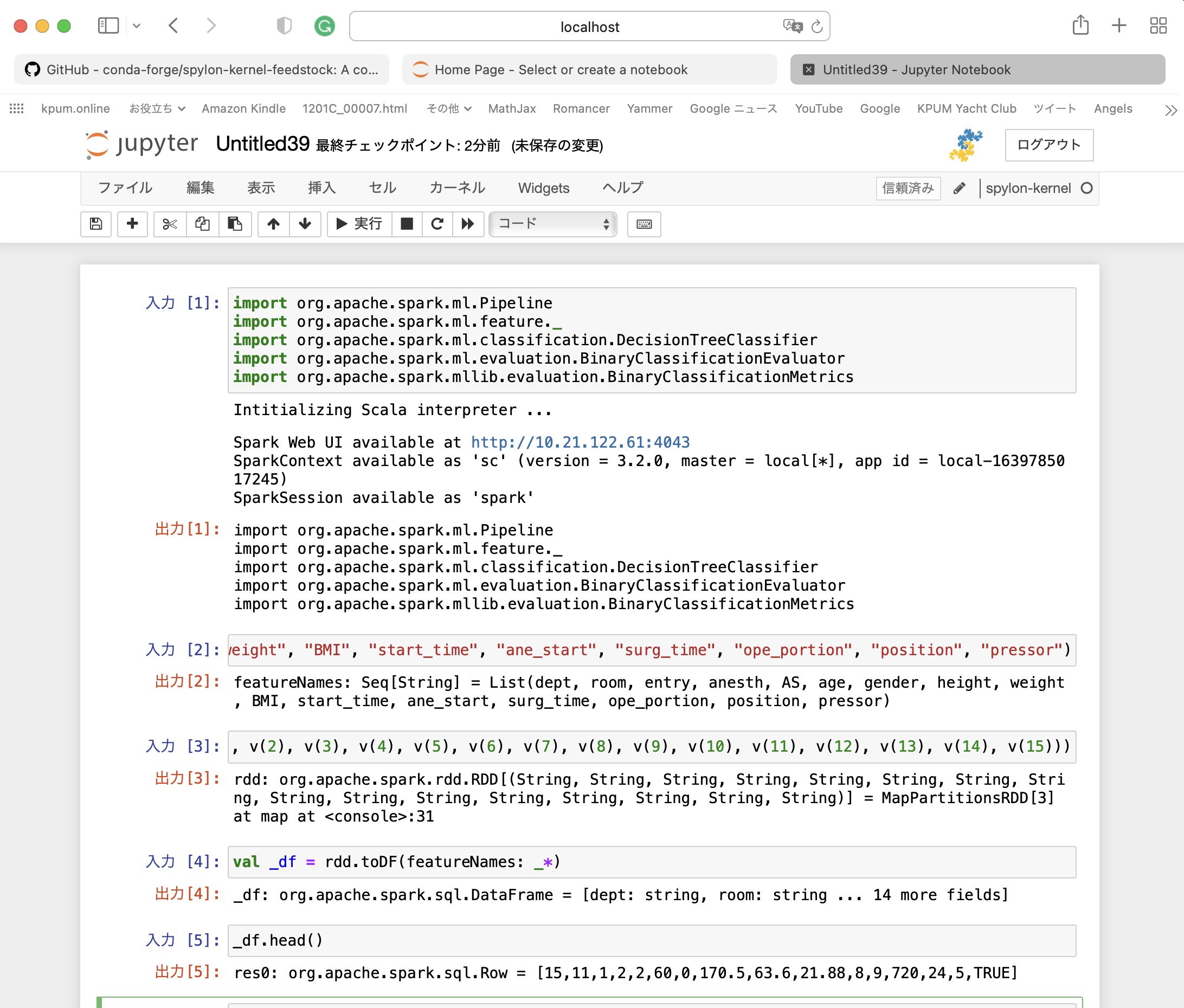
無事にJupyter Notebook (http://localhost:8889/notebooks…)から、”hdfs://localhost:9000/linkage/data_5.csv”へアクセス成功した。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 |
--#Scalaコード for Spark 機械学習 ――――――――――――――――――― 入力[1] import org.apache.spark.ml.Pipeline import org.apache.spark.ml.feature._ import org.apache.spark.ml.classification.DecisionTreeClassifier import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics Intitializing Scala interpreter ... Spark Web UI available at http://10.21.122.61:4043 SparkContext available as 'sc' (version = 3.2.0, master = local[*], app id = local-1639785017245) SparkSession available as 'spark' 出力[1] import org.apache.spark.ml.Pipeline import org.apache.spark.ml.feature._ import org.apache.spark.ml.classification.DecisionTreeClassifier import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics #DataFrameのフィールド名指定 入力[2] val featureNames = Seq("dept", "room", "entry", "anesth", "AS", "age", "gender", "height", "weight", "BMI", "start_time", "ane_start", "surg_time", "ope_portion", "position", "pressor") 出力[2] featureNames: Seq[String] = List(dept, room, entry, anesth, AS, age, gender, height, weight, BMI, start_time, ane_start, surg_time, ope_portion, position, pressor) #HDFS Data file (data_5.csvのrddへの読み込み 入力[3] val rdd = sc.textFile("hdfs://localhost:9000/linkage/data_5.csv").map(line => line.split(",")).map(v => (v(0), v(1), v(2), v(3), v(4), v(5), v(6), v(7), v(8), v(9), v(10), v(11), v(12), v(13), v(14), v(15))) 出力[3] rdd: org.apache.spark.rdd.RDD[(String, String, String, String, String, String, String, String, String, String, String, String, String, String, String, String)] = MapPartitionsRDD[3] at map at <console>:31 # rddをDataFrameへ変換 入力[4] val _df = rdd.toDF(featureNames: _*) 出力[4] _df: org.apache.spark.sql.DataFrame = [dept: string, room: string ... 14 more fields] # DataFrame _dfの1行目表示 入力[5] _df.head() 出力[5] res0: org.apache.spark.sql.Row = [15,11,1,2,2,60,0,170.5,63.6,21.88,8,9,720,24,5,TRUE] # DataFrame pressor(昇圧剤使用の有無)を数値化へ変換し, DataFrame dfとする 入力[6] val df = new StringIndexerModel(Array("FALSE", "TRUE")).setInputCol("pressor").setOutputCol("pressor2").transform(_df).drop("pressor") 出力[6] f: org.apache.spark.sql.DataFrame = [dept: string, room: string ... 14 more fields] # DataFrame dfの一行目表示 入力[7] df.head() 出力[7] res1: org.apache.spark.sql.Row = [15,11,1,2,2,60,0,170.5,63.6,21.88,8,9,720,24,5,1.0] # pressor2(昇圧剤使用の有無)に対する回帰分析 入力[8] val formula = new RFormula().setFeaturesCol("features").setLabelCol("label").setFormula("pressor2 ~ .").fit(df) 出力[8] formula: org.apache.spark.ml.feature.RFormulaModel = RFormulaModel: uid=rFormula_cb9bd054ea95, resolvedFormula=ResolvedRFormula(label=pressor2, terms=[dept,room,entry,anesth,AS,age,gender,height,weight,BMI,start_time,ane_start,surg_time,ope_portion,position], hasIntercept=true) # pressor2(昇圧剤使用の有無)に対する決定木分析 入力[9] val decisionTree = new DecisionTreeClassifier().setFeaturesCol("features").setLabelCol("pressor2").setMaxDepth(4) 出力[9] decisionTree: org.apache.spark.ml.classification.DecisionTreeClassifier = dtc_ef7aac2696c2 #パイプライン:回帰分析と決定木分析 入力[10] val pipeline = new Pipeline().setStages(Array(formula, decisionTree)) 出力[10] pipeline: org.apache.spark.ml.Pipeline = pipeline_4f27a71502d8 # DaraFrame dfを50%訓練用、50%評価用に分ける 入力[11] val trainingAndTest = df.randomSplit(Array(0.5, 0.5)) 出力[11] trainingAndTest: Array[org.apache.spark.sql.Dataset[org.apache.spark.sql.Row]] = Array([dept: string, room: string ... 14 more fields], [dept: string, room: string ... 14 more fields]) # DaraFrame dfを50%訓練用データでモデル作成 入力[12] val pipelineModel = pipeline.fit(trainingAndTest(0)) 出力[12] pipelineModel: org.apache.spark.ml.PipelineModel = pipeline_4f27a71502d8 # DaraFrame dfを50%評価用で予測 入力[13] val prediction = pipelineModel.transform(trainingAndTest(1)) 出力[13] prediction: org.apache.spark.sql.DataFrame = [dept: string, room: string ... 19 more fields] # DaraFrame dfを50%評価用での予測のAUC算定 入力[14] val auc = new BinaryClassificationEvaluator().evaluate(prediction) 出力[14] auc: Double = 0.6580880864358446 # 評価用データの個々の予測結果を閲覧 入力[15] prediction.select("features", "label", "pressor2", "prediction").show() +--------------------+-----+--------+----------+ | features|label|pressor2|prediction| +--------------------+-----+--------+----------+ |(6812,[19,25,38,4...| 0.0| 0.0| 0.0| |(6812,[19,33,38,4...| 0.0| 0.0| 1.0| |(6812,[19,33,38,4...| 0.0| 0.0| 1.0| |(6812,[19,27,38,4...| 0.0| 0.0| 1.0| |(6812,[19,27,38,4...| 0.0| 0.0| 1.0| |(6812,[14,25,39,4...| 0.0| 0.0| 1.0| |(6812,[14,25,41,5...| 0.0| 0.0| 1.0| |(6812,[14,25,40,4...| 1.0| 1.0| 1.0| |(6812,[14,25,40,4...| 1.0| 1.0| 1.0| |(6812,[14,36,38,4...| 0.0| 0.0| 1.0| |(6812,[14,35,40,4...| 1.0| 1.0| 1.0| |(6812,[14,35,40,4...| 1.0| 1.0| 1.0| |(6812,[14,35,40,4...| 0.0| 0.0| 1.0| |(6812,[14,33,38,4...| 1.0| 1.0| 1.0| |(6812,[14,33,40,4...| 1.0| 1.0| 1.0| |(6812,[14,33,40,4...| 1.0| 1.0| 1.0| |(6812,[14,33,40,4...| 1.0| 1.0| 1.0| |(6812,[14,27,38,4...| 0.0| 0.0| 1.0| |(6812,[14,27,38,4...| 0.0| 0.0| 1.0| |(6812,[14,27,39,4...| 1.0| 1.0| 1.0| +--------------------+-----+--------+----------+ only showing top 20 rows #評価用データの予測結果の総括 入力[16] val lp = prediction.select("label", "prediction") val counttotal = prediction.count() val correct = lp.filter($"label" === $"prediction").count() val wrong = lp.filter(not($"label" === $"prediction")).count() val ratioCorrect = correct.toDouble / counttotal.toDouble val ratioWrong = wrong.toDouble / counttotal.toDouble val truep = lp.filter($"prediction" === 0.0).filter($"label" === $"prediction").count() / counttotal.toDouble val truen = lp.filter($"prediction" === 1.0).filter($"label" === $"prediction").count() / counttotal.toDouble val falsep = lp.filter($"prediction" === 1.0).filter(not($"label" === $"prediction")).count() / counttotal.toDouble val falsen = lp.filter($"prediction" === 0.0).filter(not($"label" === $"prediction")).count() / counttotal.toDouble 出力[16] lp: org.apache.spark.sql.DataFrame = [label: double, prediction: double] counttotal: Long = 11837 correct: Long = 8268 wrong: Long = 3569 ratioCorrect: Double = 0.6984877925149954 ratioWrong: Double = 0.3015122074850046 truep: Double = 0.2583424854270508 truen: Double = 0.4401453070879446 falsep: Double = 0.2034299231224128 falsen: Double = 0.09808228436259188 #評価用データの予測結果の総括2 入力[17] println("Total Count: " + counttotal) println("Correct: " + correct) println("Wrong: " + wrong) println("Ratio wrong: " + ratioWrong) println("Ratio correct: " + ratioCorrect) println("Ratio wrong: " + ratioWrong) println("Ratio true positive: " + truep) println("Ratio false positive: " + falsep) println("Ratio true negative: " + truen) println("Ratio false negative: " + falsen) 出力[17] Total Count: 11837 Correct: 8268 Wrong: 3569 Ratio wrong: 0.3015122074850046 Ratio correct: 0.6984877925149954 Ratio wrong: 0.3015122074850046 Ratio true positive: 0.2583424854270508 Ratio false positive: 0.2034299231224128 Ratio true negative: 0.4401453070879446 Ratio false negative: 0.09808228436259188 |