tf.contrib.layers.fully_connected()でNeural Network
APIでは、
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
tf.contrib.layers.fully_connected( inputs, num_outputs, activation_fn=tf.nn.relu, normalizer_fn=None, normalizer_params=None, weights_initializer=initializers.xavier_initializer(), weights_regularizer=None, biases_initializer=tf.zeros_initializer(), biases_regularizer=None, reuse=None, variables_collections=None, outputs_collections=None, trainable=True, scope=None ) |
fully_connectedは、完全に接続されたレイヤーを追加する。重み変数を作成する。これは、完全に接続された重み行列を表し、これに入力が乗算されて隠れユニットのTensorが生成される。 normalizer_fn(batch_normなど)が提供されている場合は、それが適用される。そうでなければ、normalizer_fnがNoneでbiases_initializerが提供されていれば、バイアス変数が作成され、隠れユニットが追加される。 activation_fnがNoneでなければ、隠れユニットにも適用される。
注意:入力が2より大きいランクを持つ場合、入力は初期行列に重みを掛ける前に平坦化される。
引数:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
inputs:少なくともランク2のテンソルと最後の次元の静的な値。すなわち、[batch_size、depth]、[なし、なし、なし、チャンネル]。 num_outputs:整数またはlong。レイヤー内の出力ユニットの数。 activation_fn:活性化関数指定。デフォルト値はReLU関数。スキップして線形のアクティブ化を維持するには、明示的にNoneに設定。 normalizer_fn:バイアスの代わりに使用する正規化関数normalizer_fnが提供されている場合、biases_initializerとbiases_regularizerは無視され、バイアスは作成も追加もされない。ノーマライザー機能を使用しない場合、デフォルトはNoneに設定される。 normalizer_params:正規化関数のパラメータ weights_initializer:重みのためのイニシャライザ。 weights_regularizer:重みのためのオプションの正則化子。 biases_initializer:バイアスのためのイニシャライザ。 Noneの場合、バイアスをスキップ。 biases_regularizer:バイアスのためのオプションの正則化子。 reuse:レイヤーとその変数を再利用するかどうか。レイヤスコープを再利用できるようにするためには与えなければならない。 variables_collections:すべての変数のコレクションのオプションのリスト、または変数ごとに異なるコレクションのリストを含む辞書。 output_collections:出力を追加するためのコレクション。 trainable:TrueならグラフコレクションGraphKeys.TRAINABLE_VARIABLESに変数も追加(tf.Variableを参照)。 scope:variable_scopeのオプションのスコープ。 |
戻り値: 一連の操作の結果を表すテンソル変数。
Raises: ValueError:xのランクが2未満の場合、または最後の次元が設定されていない場合
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
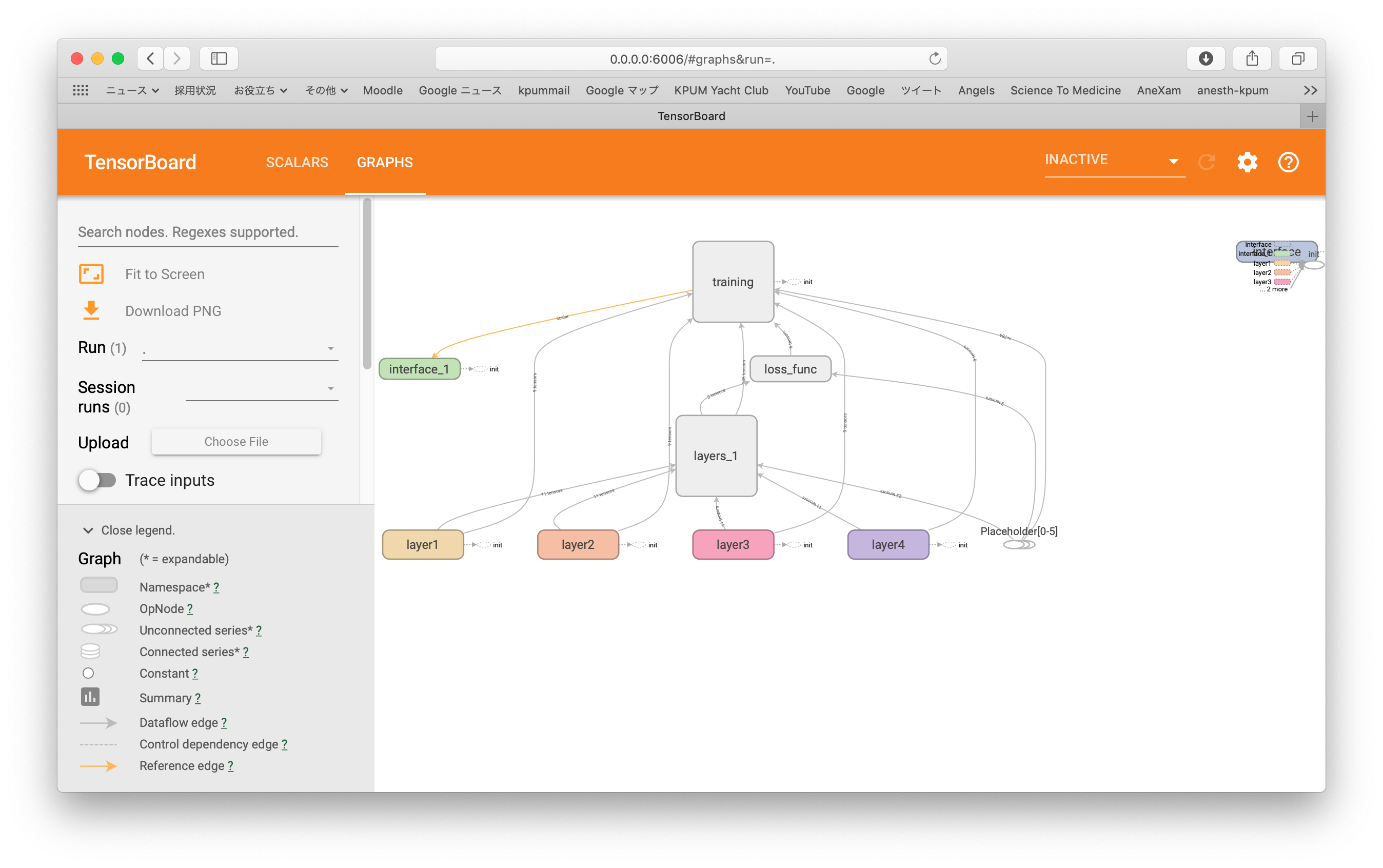
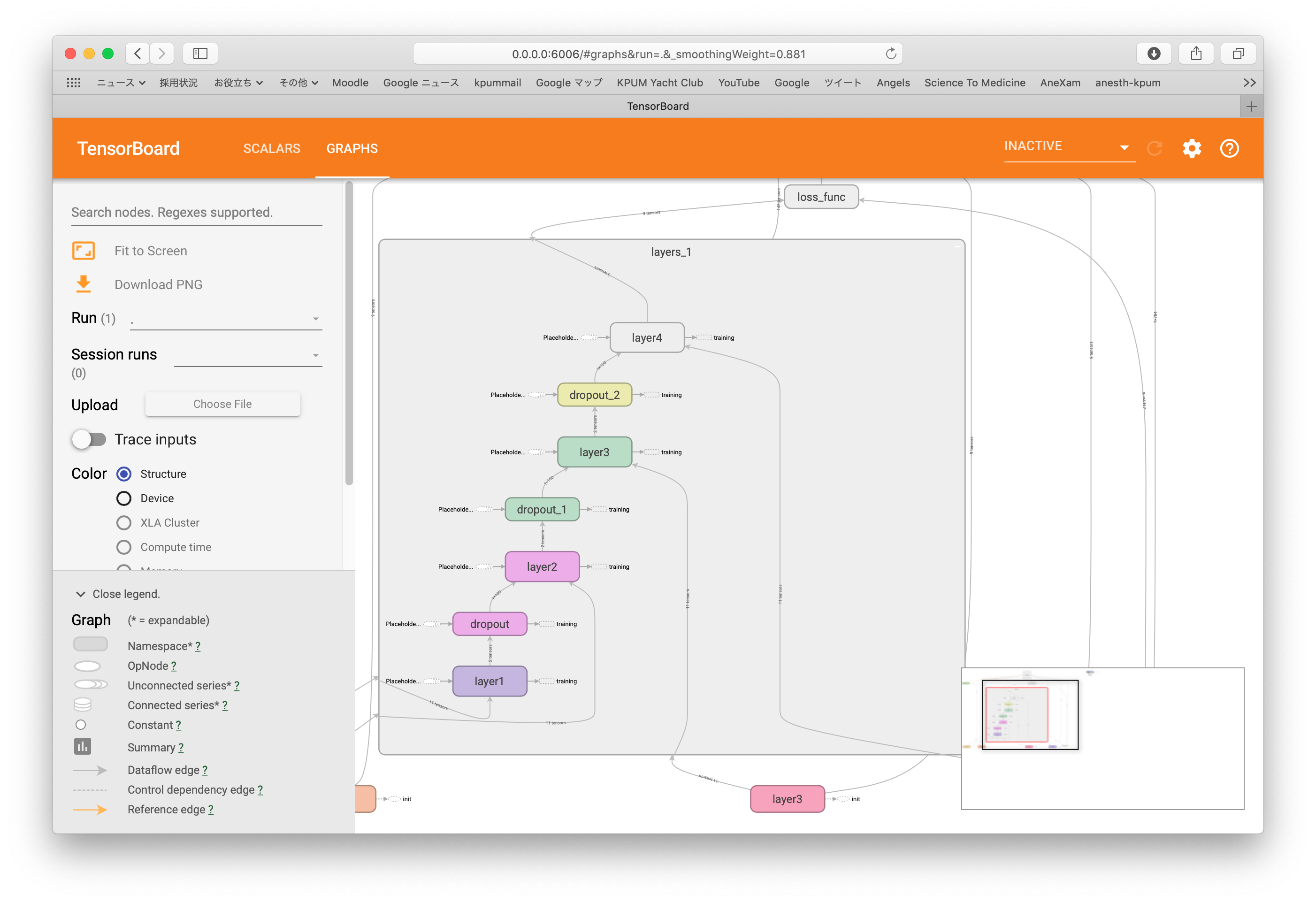
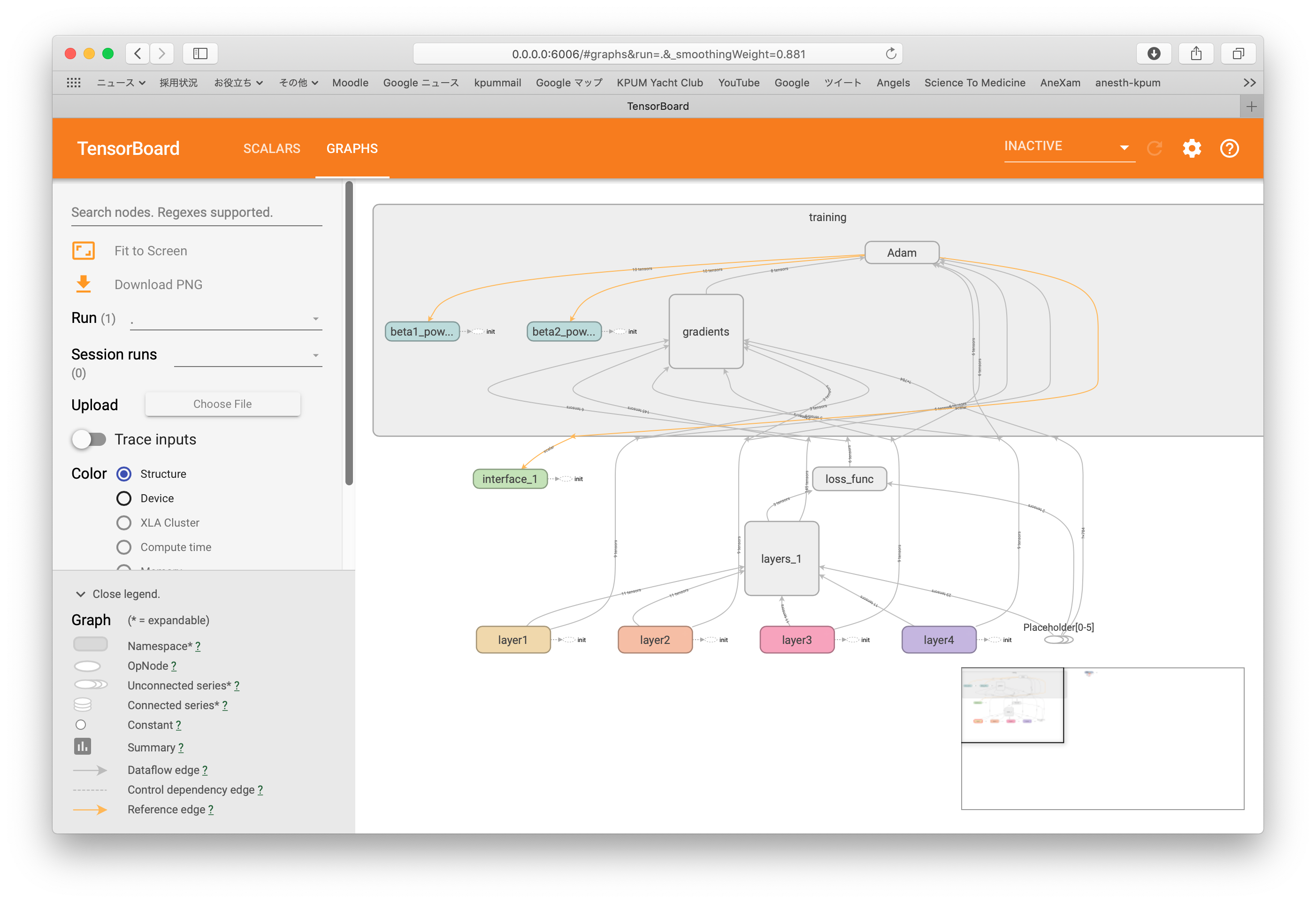
import tensorflow as tf import tensorflow.contrib.learn as learn # MNISTデータ読み込み from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("/tmp/data/", one_hot = True) # プレースホルダー設定 image = tf.placeholder(tf.float32, [None, 784]) #28x28行列要素を収める label = tf.placeholder(tf.float32, [None, 10]) #0〜9の数字ラベルを収める train = tf.placeholder(tf.bool) with tf.name_scope('interface') as scope: step_var = tf.Variable(0, trainable=False) # レイヤー設定 hid_nodes = 100 out_nodes = 10 keep_prob = 0.5 # レイヤー生成 with tf.name_scope('layers') as scope: with tf.contrib.framework.arg_scope( [tf.contrib.layers.fully_connected], normalizer_fn=tf.contrib.layers.batch_norm, normalizer_params={'is_training': train}): layer1 = tf.contrib.layers.fully_connected(image, hid_nodes, scope='layer1') layer1_drop = tf.layers.dropout(layer1, keep_prob, training=train) layer2 = tf.contrib.layers.fully_connected(layer1_drop, hid_nodes, scope='layer2') layer2_drop = tf.layers.dropout(layer2, keep_prob, training=train) layer3 = tf.contrib.layers.fully_connected(layer2_drop, hid_nodes, scope='layer3') layer3_drop = tf.layers.dropout(layer3, keep_prob, training=train) out_layer = tf.contrib.layers.fully_connected(layer3_drop, out_nodes, activation_fn=None, scope='layer4') with tf.name_scope('loss_func') as scope: # 損失関数 loss = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits_v2( logits=out_layer, labels=label)) summary_op1 = tf.summary.scalar('loss1', loss) summary_op2 = tf.summary.scalar('loss2', loss) with tf.name_scope('training') as scope: # 最適化 learning_rate = 0.01 num_epochs = 15 batch_size = 100 num_batches = int(mnist.train.num_examples/batch_size) optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss, global_step=step_var) # 変数初期化 init = tf.global_variables_initializer() summary = tf.summary.merge_all() # セッション立ち上げ with tf.Session() as sess: writer = tf.summary.FileWriter("logs", graph=sess.graph) sess.run(init) # エポックループ for epoch in range(num_epochs): # バッチループ for batch in range(num_batches): image_batch, label_batch = mnist.train.next_batch(batch_size) step = sess.run(step_var) sess.run(optimizer, feed_dict={image: image_batch, label: label_batch, train: True}) summary_op1R = sess.run(summary_op1, feed_dict={image: image_batch, label: label_batch, train: True}) summary_op2R = sess.run(summary_op2, feed_dict={image: image_batch, label: label_batch, train: True}) writer.add_summary(summary_op1R, global_step=step) writer.add_summary(summary_op2R, epoch) # 正答率算定 prediction = tf.equal(tf.argmax(out_layer, 1), tf.argmax(label, 1)) success = tf.reduce_mean(tf.cast(prediction, tf.float32)) print('Correction %: ', 100 * sess.run(success, feed_dict={image: mnist.test.images, label: mnist.test.labels, train: False}) |
出力:
|
1 2 3 4 5 |
Extracting /tmp/data/train-images-idx3-ubyte.gz Extracting /tmp/data/train-labels-idx1-ubyte.gz Extracting /tmp/data/t10k-images-idx3-ubyte.gz Extracting /tmp/data/t10k-labels-idx1-ubyte.gz Correction %: 94.5900022983551 |
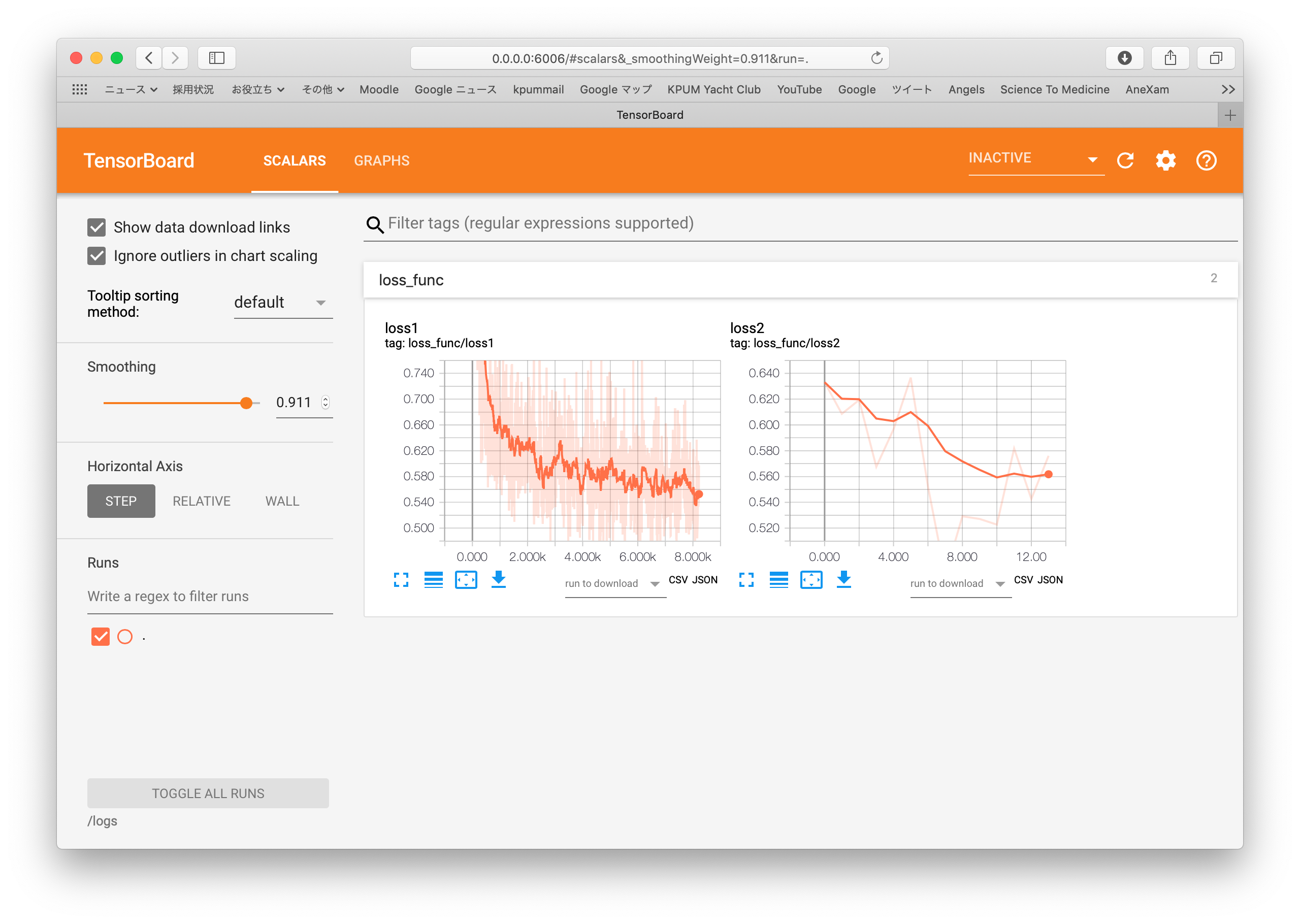
損失関数の変化をバッチごと、エポックごとでそれぞれ描いたものを以下に示す。