PySparkに挑戦:テキストブックは、入門PySpark
—————————
~/.bash_profile
にパスを追加
|
1 2 3 4 5 6 |
#pySpark #export PATH=/opt/spark-2.1.1-bin-hadoop2.7/bin:$PATH export PATH=/opt/spark-2.3.1-bin-hadoop2.7/bin:$PATH export PYSPARK_PYTHON=$HOME/anaconda3/bin/python3 export PYSPARK_DRIVER_PYTHON=jupyter export PYSPARK_DRIVER_PYTHON_OPTS='notebook' pyspark |
で、Jupyter Notebookであとは対応。
|
1 |
> pyspark |
Generate your own DataFrame
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 |
# Generate our own JSON data # This way we don't have to access the file system yet. stringJSONRDD = sc.parallelize((""" { "id": "123", "name": "Katie", "age": 19, "eyeColor": "brown" }""", """{ "id": "234", "name": "Michael", "age": 22, "eyeColor": "green" }""", """{ "id": "345", "name": "Simone", "age": 23, "eyeColor": "blue" }""") ) # Create DataFrame swimmersJSON = spark.read.json(stringJSONRDD) # Create temporary table swimmersJSON.createOrReplaceTempView("swimmersJSON") # DataFrame API swimmersJSON.show() +---+--------+---+-------+ |age|eyeColor| id| name| +---+--------+---+-------+ | 19| brown|123| Katie| | 22| green|234|Michael| | 23| blue|345| Simone| +---+--------+---+-------+ # SQL Query spark.sql("select * from swimmersJSON").collect() [Row(age=19, eyeColor='brown', id='123', name='Katie'), Row(age=22, eyeColor='green', id='234', name='Michael'), Row(age=23, eyeColor='blue', id='345', name='Simone')] # Print the schema swimmersJSON.printSchema() root |-- age: long (nullable = true) |-- eyeColor: string (nullable = true) |-- id: string (nullable = true) |-- name: string (nullable = true) from pyspark.sql.types import * # Generate our own CSV data # This way we don't have to access the file system yet. stringCSVRDD = sc.parallelize([(123, 'Katie', 19, 'brown'), (234, 'Michael', 22, 'green'), (345, 'Simone', 23, 'blue')]) # The schema is encoded in a string, using StructType we define the schema using various pyspark.sql.types schemaString = "id name age eyeColor" schema = StructType([ StructField("id", LongType(), True), StructField("name", StringType(), True), StructField("age", LongType(), True), StructField("eyeColor", StringType(), True) ]) # Apply the schema to the RDD and Create DataFrame swimmers = spark.createDataFrame(stringCSVRDD, schema) # Creates a temporary view using the DataFrame swimmers.createOrReplaceTempView("swimmers") # Print the schema # Notice that we have redefined id as Long (instead of String) swimmers.printSchema() root |-- id: long (nullable = true) |-- name: string (nullable = true) |-- age: long (nullable = true) |-- eyeColor: string (nullable = true) # Execute SQL Query and return the data spark.sql("select * from swimmers").show() +---+-------+---+--------+ | id| name|age|eyeColor| +---+-------+---+--------+ |123| Katie| 19| brown| |234|Michael| 22| green| |345| Simone| 23| blue| +---+-------+---+--------+ # Get count of rows in SQL spark.sql("select count(1) from swimmers").show() +--------+ |count(1)| +--------+ | 3| +--------+ # Query id and age for swimmers with age = 22 via DataFrame API swimmers.select("id", "age").filter("age = 22").show() +---+---+ | id|age| +---+---+ |234| 22| +---+---+ # Query id and age for swimmers with age = 22 via DataFrame API in another way swimmers.select(swimmers.id, swimmers.age).filter(swimmers.age == 22).show() +---+---+ | id|age| +---+---+ |234| 22| +---+---+ # Query id and age for swimmers with age = 22 in SQL spark.sql("select id, age from swimmers where age = 22").show() +---+---+ | id|age| +---+---+ |234| 22| +---+---+ # Query name and eye color for swimmers with eye color starting with the letter 'b' spark.sql("select name, eyeColor from swimmers where eyeColor like 'b%'").show() +------+--------+ | name|eyeColor| +------+--------+ | Katie| brown| |Simone| blue| +------+--------+ # Show the values swimmers.show() +---+-------+---+--------+ | id| name|age|eyeColor| +---+-------+---+--------+ |123| Katie| 19| brown| |234|Michael| 22| green| |345| Simone| 23| blue| +---+-------+---+--------+ # Get count of rows swimmers.count() 3 # Get the id, age where age = 22 swimmers.select("id", "age").filter("age = 22").show() +---+---+ | id|age| +---+---+ |234| 22| +---+---+ # Get the name, eyeColor where eyeColor like 'b%' swimmers.select("name", "eyeColor").filter("eyeColor like 'b%'").show() +------+--------+ | name|eyeColor| +------+--------+ | Katie| brown| |Simone| blue| +------+--------+ |
On-Time Flight Performance
以下、Jupyter Notebookから、DataBricks Community Versionに移行する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
flightPerfFilePath = "/databricks-datasets/flights/departuredelays.csv" airportsFilePath = "/databricks-datasets/flights/airport-codes-na.txt" # Obtain Airports dataset airports = spark.read.csv(airportsFilePath, header='true', inferSchema='true', sep='\t') airports.createOrReplaceTempView("airports") # Obtain Departure Delays dataset flightPerf = spark.read.csv(flightPerfFilePath, header='true') flightPerf.createOrReplaceTempView("FlightPerformance") # Cache the Departure Delays dataset flightPerf.cache() spark.sql("select a.City, f.origin, sum(f.delay) as Delays from FlightPerformance f join airports a on a.IATA = f.origin where a.State = 'WA' group by a.City, f.origin order by sum(f.delay) desc").show() |
|
1 2 3 4 5 6 7 8 9 10 |
%sql -- select a.City, f.origin, sum(f.delay) as Delays from FlightPerformance f join airports a on a.IATA = f.origin where a.State = 'WA' group by a.City, f.origin order by sum(f.delay) desc |
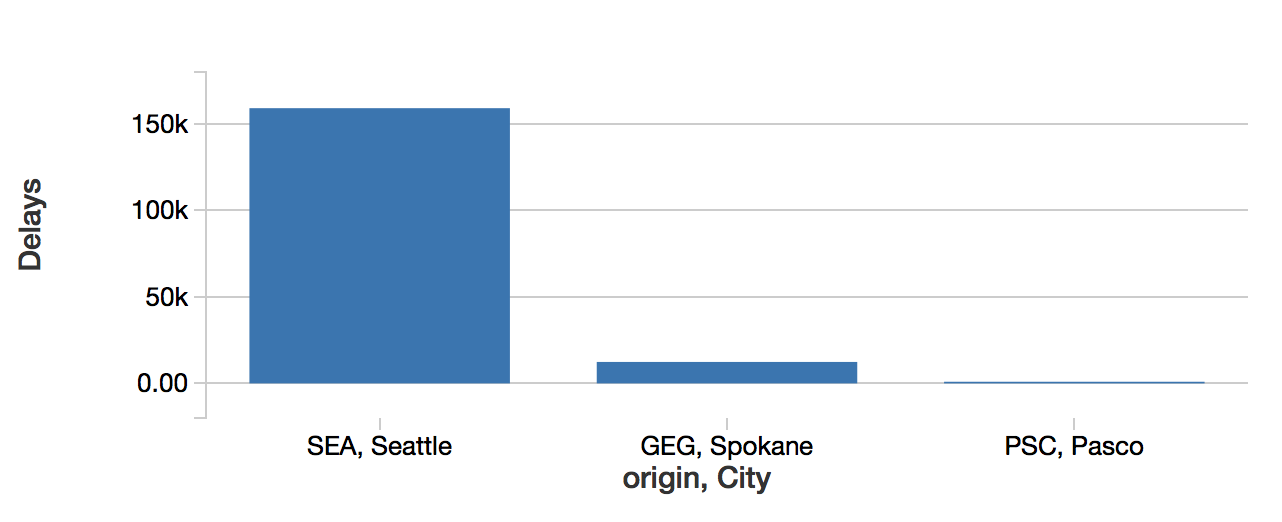
|
1 |
spark.sql("select a.State, sum(f.delay) as Delays from FlightPerformance f join airports a on a.IATA = f.origin where a.Country = 'USA' group by a.State ").show() |
|
1 2 3 4 5 6 7 8 9 |
%sql -- Query Sum of Flight Delays by State (for the US) select a.State, sum(f.delay) as Delays from FlightPerformance f join airports a on a.IATA = f.origin where a.Country = 'USA' group by a.State |
