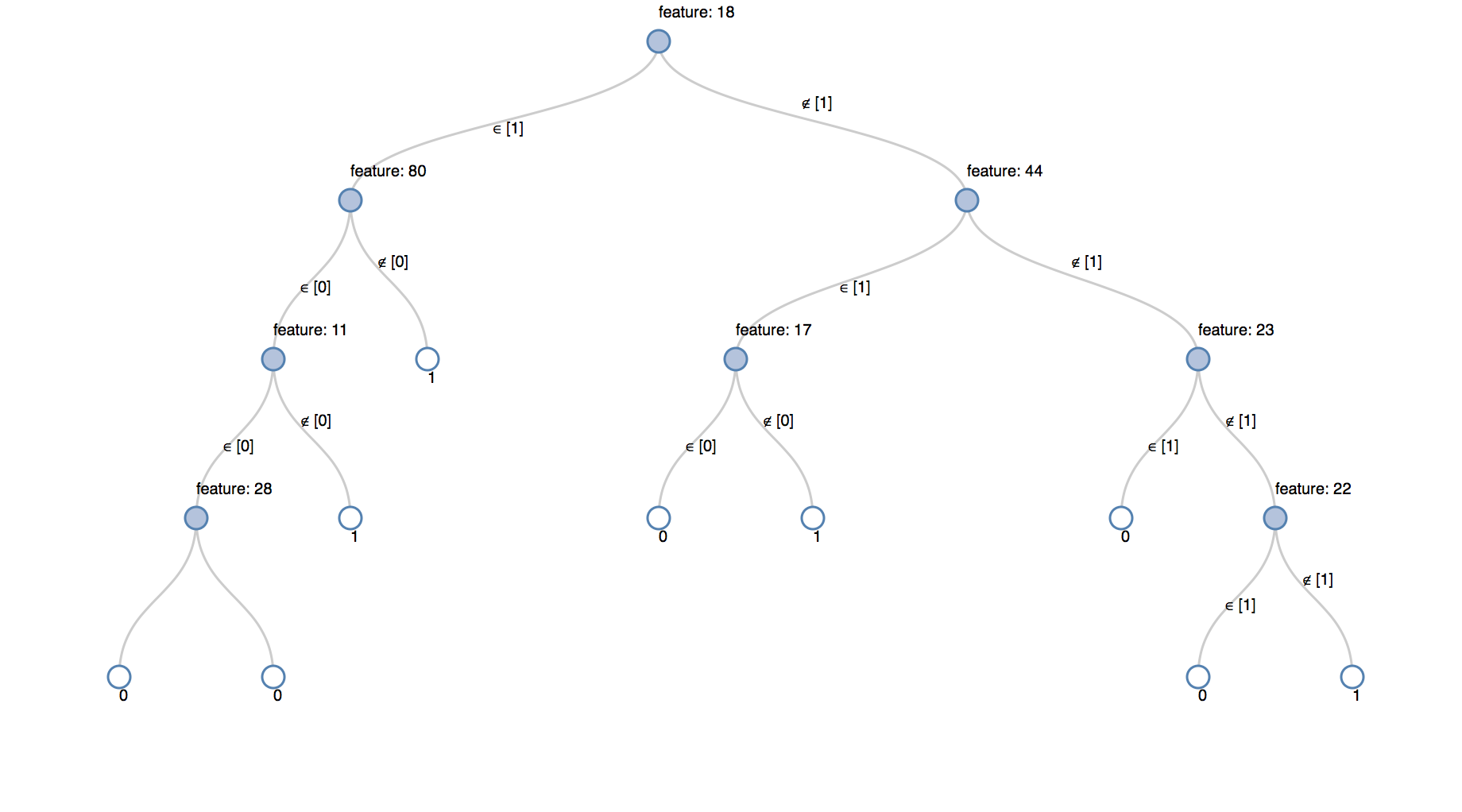
「詳解Apache Spark」の例で毒キノコの外見判別ー決定木
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
データは、UCIの機械学習さいとより、
https://archive.ics.uci.edu/ml/machine-learning-databases/mushroom/
agaricus-lepiota.data
をダウンロードする。
プログラムコード例は、
https://github.com/yu-iskw/gihyo-spark-book-example
のCh07-きのこの可食・有毒の識別のサンプルコード
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
データは、
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
p,x,s,n,t,p,f,c,n,k,e,e,s,s,w,w,p,w,o,p,k,s,u e,x,s,y,t,a,f,c,b,k,e,c,s,s,w,w,p,w,o,p,n,n,g e,b,s,w,t,l,f,c,b,n,e,c,s,s,w,w,p,w,o,p,n,n,m p,x,y,w,t,p,f,c,n,n,e,e,s,s,w,w,p,w,o,p,k,s,u e,x,s,g,f,n,f,w,b,k,t,e,s,s,w,w,p,w,o,e,n,a,g e,x,y,y,t,a,f,c,b,n,e,c,s,s,w,w,p,w,o,p,k,n,g e,b,s,w,t,a,f,c,b,g,e,c,s,s,w,w,p,w,o,p,k,n,m e,b,y,w,t,l,f,c,b,n,e,c,s,s,w,w,p,w,o,p,n,s,m p,x,y,w,t,p,f,c,n,p,e,e,s,s,w,w,p,w,o,p,k,v,g e,b,s,y,t,a,f,c,b,g,e,c,s,s,w,w,p,w,o,p,k,s,m e,x,y,y,t,l,f,c,b,g,e,c,s,s,w,w,p,w,o,p,n,n,g e,x,y,y,t,a,f,c,b,n,e,c,s,s,w,w,p,w,o,p,k,s,m ........ |
と、23列の文字。始めのe: edible, p: poisonous
Class Distribution:
— edible: 4208 (51.8%)
— poisonous: 3916 (48.2%)
— total: 8124 instances
他の22項目は、
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
1. cap-shape: bell=b,conical=c,convex=x,flat=f, knobbed=k,sunken=s 2. cap-surface: fibrous=f,grooves=g,scaly=y,smooth=s 3. cap-color: brown=n,buff=b,cinnamon=c,gray=g,green=r, pink=p,purple=u,red=e,white=w,yellow=y 4. bruises?: bruises=t,no=f 5. odor: almond=a,anise=l,creosote=c,fishy=y,foul=f, musty=m,none=n,pungent=p,spicy=s 6. gill-attachment: attached=a,descending=d,free=f,notched=n 7. gill-spacing: close=c,crowded=w,distant=d 8. gill-size: broad=b,narrow=n 9. gill-color: black=k,brown=n,buff=b,chocolate=h,gray=g, green=r,orange=o,pink=p,purple=u,red=e, white=w,yellow=y 10. stalk-shape: enlarging=e,tapering=t 11. stalk-root: bulbous=b,club=c,cup=u,equal=e, rhizomorphs=z,rooted=r,missing=? 12. stalk-surface-above-ring: fibrous=f,scaly=y,silky=k,smooth=s 13. stalk-surface-below-ring: fibrous=f,scaly=y,silky=k,smooth=s 14. stalk-color-above-ring: brown=n,buff=b,cinnamon=c,gray=g,orange=o, pink=p,red=e,white=w,yellow=y 15. stalk-color-below-ring: brown=n,buff=b,cinnamon=c,gray=g,orange=o, pink=p,red=e,white=w,yellow=y 16. veil-type: partial=p,universal=u 17. veil-color: brown=n,orange=o,white=w,yellow=y 18. ring-number: none=n,one=o,two=t 19. ring-type: cobwebby=c,evanescent=e,flaring=f,large=l, none=n,pendant=p,sheathing=s,zone=z 20. spore-print-color: black=k,brown=n,buff=b,chocolate=h,green=r, orange=o,purple=u,white=w,yellow=y 21. population: abundant=a,clustered=c,numerous=n, scattered=s,several=v,solitary=y 22. habitat: grasses=g,leaves=l,meadows=m,paths=p, urban=u,waste=w,woods=d |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 |
scala> import org.apache.spark.ml.Pipeline import org.apache.spark.ml.Pipeline scala> import org.apache.spark.ml.classification.DecisionTreeClassifier import org.apache.spark.ml.classification.DecisionTreeClassifier scala> import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator scala> import org.apache.spark.ml.feature._ import org.apache.spark.ml.feature._ scala> import org.apache.spark.sql.SQLContext import org.apache.spark.sql.SQLContext scala> import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.{SparkConf, SparkContext} // 以下は DataFrame のカラム名として利用 (veil-type は除く) scala> val featureNames = Seq("_edible", "cap-shape", "cap-surface", "cap-color", "bruises?", "odor", "gill-attachment", "gill-spacing", "gill-size", "gill-color", "stalk-shape", "stalk-root", "stalk-surface-above-ring", "stalk-surface-below-ring", "stalk-color-above-ring", "stalk-color-below-ring", "veil-color", "ring-number", "ring-type", "spore-print-color", "population", "habitat") featureNames: Seq[String] = List(_edible, cap-shape, cap-surface, cap-color, bruises?, odor, gill-attachment, gill-spacing, gill-size, gill-color, stalk-shape, stalk-root, stalk-surface-above-ring, stalk-surface-below-ring, stalk-color-above-ring, stalk-color-below-ring, veil-color, ring-number, ring-type, spore-print-color, population, habitat) // 1. データセットをロードしてタプルの RDD として保持 // (veil-type に相当する特徴量 v(16) はタプルに含めない) scala> val rdd = sc.textFile("/Users/*******/agaricus-lepiota.data").map(line => line.split(",")).map(v => (v(0), v(1), v(2), v(3), v(4), v(5), v(6), v(7), v(8), v(9), v(10), v(11), v(12), | v(13), v(14), v(15), v(17), v(18), v(19), v(20), v(21), v(22))) rdd: org.apache.spark.rdd.RDD[(String, String, String, String, String, String, String, String, String, String, String, String, String, String, String, String, String, String, String, String, String, String)] = MapPartitionsRDD[43] at map at <console>:37 // 2. RDD から DataFrame に変換 scala> val _df = rdd.toDF(featureNames: _*) _df: org.apache.spark.sql.DataFrame = [_edible: string, cap-shape: string ... 20 more fields] scala> _df.first res3: org.apache.spark.sql.Row = [p,x,s,n,t,p,f,c,n,k,e,e,s,s,w,w,w,o,p,k,s,u] // 3. 文字列表現されたラベル ("e", "p") を数値に変換 scala> val df = new StringIndexerModel(Array("e", "p")).setInputCol("_edible").setOutputCol("edible").transform(_df).drop("_edible").drop("veil-type") df: org.apache.spark.sql.DataFrame = [cap-shape: string, cap-surface: string ... 20 more fields] scala> df res1: org.apache.spark.sql.DataFrame = [cap-shape: string, cap-surface: string ... 20 more fields] scala> df.first res2: org.apache.spark.sql.Row = [x,s,n,t,p,f,c,n,k,e,e,s,s,w,w,w,o,p,k,s,u,1.0] // 4. R のモデル式で特徴選択モデルを構築 scala> val formula = new RFormula().setFeaturesCol("features").setLabelCol("label").setFormula("edible ~ .").fit(df) formula: org.apache.spark.ml.feature.RFormulaModel = RFormulaModel(ResolvedRFormula(label=edible, terms=[cap-shape,cap-surface,cap-color,bruises?,odor,gill-attachment,gill-spacing,gill-size,gill-color,stalk-shape,stalk-root,stalk-surface-above-ring,stalk-surface-below-ring,stalk-color-above-ring,stalk-color-below-ring,veil-color,ring-number,ring-type,spore-print-color,population,habitat], hasIntercept=true)) (uid=rFormula_8d15024faeed) // 5. 決定木の学習器を準備 // 木の深さ (maxDepth) のパラメータのみ設定する scala> val decisionTree = new DecisionTreeClassifier().setFeaturesCol("features").setLabelCol("edible").setMaxDepth(4) decisionTree: org.apache.spark.ml.classification.DecisionTreeClassifier = dtc_c54e11de22cf // 6. 特徴選択から学習までのパイプラインを構築 scala> val pipeline = new Pipeline().setStages(Array(formula, decisionTree)) pipeline: org.apache.spark.ml.Pipeline = pipeline_5164bd3db965 // 7. データセットの分割 (学習用と検証用) scala> val trainingAndTest = df.randomSplit(Array(0.5, 0.5)) trainingAndTest: Array[org.apache.spark.sql.Dataset[org.apache.spark.sql.Row]] = Array([cap-shape: string, cap-surface: string ... 20 more fields], [cap-shape: string, cap-surface: string ... 20 more fields]) // 8. パイプライン処理による決定木の予測モデル構築 scala> val pipelineModel = pipeline.fit(trainingAndTest(0)) pipelineModel: org.apache.spark.ml.PipelineModel = pipeline_5164bd3db965 // 9. 予測モデルを用いて検証用データに対して予測 scala> val prediction = pipelineModel.transform(trainingAndTest(1)) prediction: org.apache.spark.sql.DataFrame = [cap-shape: string, cap-surface: string ... 25 more fields] // 10. 予測結果から評価メトリクス (AUC) を計算 scala> val auc = new BinaryClassificationEvaluator().evaluate(prediction) auc: Double = 0.9998334110579613 scala> println(auc) 0.9998334110579613 //以下、データ構造の確認 scala> df res2: org.apache.spark.sql.DataFrame = [cap-shape: string, cap-surface: string ... 20 more fields] scala> df.first res3: org.apache.spark.sql.Row = [x,s,n,t,p,f,c,n,k,e,e,s,s,w,w,w,o,p,k,s,u,1.0] scala> df.take(10).foreach(println) [x,s,n,t,p,f,c,n,k,e,e,s,s,w,w,w,o,p,k,s,u,1.0] [x,s,y,t,a,f,c,b,k,e,c,s,s,w,w,w,o,p,n,n,g,0.0] [b,s,w,t,l,f,c,b,n,e,c,s,s,w,w,w,o,p,n,n,m,0.0] [x,y,w,t,p,f,c,n,n,e,e,s,s,w,w,w,o,p,k,s,u,1.0] [x,s,g,f,n,f,w,b,k,t,e,s,s,w,w,w,o,e,n,a,g,0.0] [x,y,y,t,a,f,c,b,n,e,c,s,s,w,w,w,o,p,k,n,g,0.0] [b,s,w,t,a,f,c,b,g,e,c,s,s,w,w,w,o,p,k,n,m,0.0] [b,y,w,t,l,f,c,b,n,e,c,s,s,w,w,w,o,p,n,s,m,0.0] [x,y,w,t,p,f,c,n,p,e,e,s,s,w,w,w,o,p,k,v,g,1.0] [b,s,y,t,a,f,c,b,g,e,c,s,s,w,w,w,o,p,k,s,m,0.0] scala> _df.first res5: org.apache.spark.sql.Row = [p,x,s,n,t,p,f,c,n,k,e,e,s,s,w,w,w,o,p,k,s,u] scala> _df.take(10).foreach(println) [p,x,s,n,t,p,f,c,n,k,e,e,s,s,w,w,w,o,p,k,s,u] [e,x,s,y,t,a,f,c,b,k,e,c,s,s,w,w,w,o,p,n,n,g] [e,b,s,w,t,l,f,c,b,n,e,c,s,s,w,w,w,o,p,n,n,m] [p,x,y,w,t,p,f,c,n,n,e,e,s,s,w,w,w,o,p,k,s,u] [e,x,s,g,f,n,f,w,b,k,t,e,s,s,w,w,w,o,e,n,a,g] [e,x,y,y,t,a,f,c,b,n,e,c,s,s,w,w,w,o,p,k,n,g] [e,b,s,w,t,a,f,c,b,g,e,c,s,s,w,w,w,o,p,k,n,m] [e,b,y,w,t,l,f,c,b,n,e,c,s,s,w,w,w,o,p,n,s,m] [p,x,y,w,t,p,f,c,n,p,e,e,s,s,w,w,w,o,p,k,v,g] [e,b,s,y,t,a,f,c,b,g,e,c,s,s,w,w,w,o,p,k,s,m] |
解析結果をいろいろと弄ってみる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 |
scala> prediction.select("cap-shape", "cap-surface", "cap-color").show(5) 18/11/16 12:37:00 WARN Utils: Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.debug.maxToStringFields' in SparkEnv.conf. +---------+-----------+---------+ |cap-shape|cap-surface|cap-color| +---------+-----------+---------+ | b| f| g| | b| f| g| | b| f| g| | b| f| g| | b| f| g| +---------+-----------+---------+ only showing top 5 rows scala> prediction.select("cap-shape", "cap-surface", "cap-color", "edible").show(5) +---------+-----------+---------+------+ |cap-shape|cap-surface|cap-color|edible| +---------+-----------+---------+------+ | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| +---------+-----------+---------+------+ only showing top 5 rows scala> prediction.select("cap-shape", "cap-surface", "cap-color", "edible").show(10) +---------+-----------+---------+------+ |cap-shape|cap-surface|cap-color|edible| +---------+-----------+---------+------+ | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| +---------+-----------+---------+------+ only showing top 10 rows scala> prediction.select("cap-shape", "cap-surface", "cap-color", "edible").show(50) +---------+-----------+---------+------+ |cap-shape|cap-surface|cap-color|edible| +---------+-----------+---------+------+ | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| g| 0.0| | b| f| w| 0.0| | b| f| w| 0.0| | b| f| w| 0.0| | b| f| w| 0.0| | b| f| w| 0.0| | b| f| w| 0.0| | b| f| w| 0.0| | b| f| w| 0.0| | b| f| w| 0.0| | b| f| w| 0.0| | b| f| w| 0.0| | b| f| w| 0.0| | b| f| w| 0.0| | b| f| y| 1.0| | b| g| w| 1.0| | b| s| b| 1.0| | b| s| b| 1.0| | b| s| g| 0.0| | b| s| g| 0.0| | b| s| g| 0.0| | b| s| g| 0.0| | b| s| g| 0.0| | b| s| g| 0.0| | b| s| g| 0.0| | b| s| g| 0.0| | b| s| g| 0.0| | b| s| n| 0.0| | b| s| n| 0.0| | b| s| n| 0.0| | b| s| n| 0.0| | b| s| n| 0.0| | b| s| n| 0.0| | b| s| n| 0.0| | b| s| n| 0.0| | b| s| n| 0.0| | b| s| n| 0.0| | b| s| n| 0.0| +---------+-----------+---------+------+ only showing top 50 rows scala> pipelineModel.write.overwrite().save("/Users/*******/spark-logistic-regression-model") scala> import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel} import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel} scala> val tree = pipelineModel.stages.last.asInstanceOf[DecisionTreeClassificationModel] tree: org.apache.spark.ml.classification.DecisionTreeClassificationModel = DecisionTreeClassificationModel (uid=dtc_489b64b7897f) of depth 4 with 17 nodes |
Databricksを用いて、可視化してみる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import org.apache.spark.ml.Pipeline import org.apache.spark.ml.classification.DecisionTreeClassifier import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator import org.apache.spark.ml.feature._ import org.apache.spark.sql.SQLContext import org.apache.spark.{SparkConf, SparkContext} val featureNames = Seq("_edible", "cap-shape", "cap-surface", "cap-color", "bruises?", "odor", "gill-attachment", "gill-spacing", "gill-size", "gill-color", "stalk-shape", "stalk-root", "stalk-surface-above-ring", "stalk-surface-below-ring", "stalk-color-above-ring", "stalk-color-below-ring", "veil-color", "ring-number", "ring-type", "spore-print-color", "population", "habitat") val rdd = sc.textFile("/FileStore/tables/agaricus_lepiota-9ffca.data").map(line => line.split(",")).map(v => (v(0), v(1), v(2), v(3), v(4), v(5), v(6), v(7), v(8), v(9), v(10), v(11), v(12),v(13), v(14), v(15), v(17), v(18), v(19), v(20), v(21), v(22))) val _df = rdd.toDF(featureNames: _*) _df.first val df = new StringIndexerModel(Array("e", "p")).setInputCol("_edible").setOutputCol("edible").transform(_df).drop("_edible").drop("veil-type") val formula = new RFormula().setFeaturesCol("features").setLabelCol("label").setFormula("edible ~ .").fit(df) val decisionTree = new DecisionTreeClassifier().setFeaturesCol("features").setLabelCol("edible").setMaxDepth(4) val pipeline = new Pipeline().setStages(Array(formula, decisionTree)) val trainingAndTest = df.randomSplit(Array(0.5, 0.5)) val pipelineModel = pipeline.fit(trainingAndTest(0)) val prediction = pipelineModel.transform(trainingAndTest(1)) val auc = new BinaryClassificationEvaluator().evaluate(prediction) import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel} val tree = pipelineModel.stages.last.asInstanceOf[DecisionTreeClassificationModel] display(tree) |