大規模データ分散処理を支えるHadoop Distributed File Systemについて、チェックしておく。
手順を間違えると、エラー出まくりで、1-2日を棒に振ることになるので要注意。
おおまかなHadoopの基本概念は、SSHというリモートアクセスのプロトコールを通じて、ネット上からアクセス可能なhdfsという仮想のファイル構造を構築することから始まる。
SSHを構築して、Hadoop Namenode formatで仮想ファイル構造hdfsを作成し、sbinから起動する。
無事に起動できれば、hadoop fs コマンド群で、フォルダを作成したり、一般ファイル構成から、このhdfsにコピーしたりする。詳細な設定により、巨大なデータを複数のコンピュータ上に保存して、分散処理の基盤を作成することができる。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
Hadoop 3.3.1のインストール:
|
1 |
brew install hadoop |
で、/opt/homebrew/Cellar/hadoop/3.3.1 にインストールされる。
/opt/homebrew/Cellar/hadoop/3.3.1/libexec/etc/hadoop/core-site.xmlに以下を追加。
|
1 2 3 4 5 6 7 8 9 10 11 |
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/opt/homebrew/Cellar/hadoop/hdfs/tmp</value> <description>A base for other temporary directories.</description> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration> |
/opt/homebrew/Cellar/hadoop/3.3.1/libexec/etc/hadoop/mapred-site.xmlに以下を追加。
|
1 2 3 4 5 6 |
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9010</value> </property> </configuration> |
/opt/homebrew/Cellar/hadoop/3.3.1/libexec/etc/hadoop/hdfs-site.xmlに以下を追加。
|
1 2 3 4 5 6 |
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> |
$HADOOP_HOME/etc/hadoop/hadoop-env.shの$JAVA_HOME variableをいかに設定(大事!でないとyarn起動でトラブルよ!)
|
1 |
export JAVA_HOME=/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home/ |
SSH localhostの設定:localhostにsshできるようにする。
|
1 |
~/.ssh/id_rsaと~/.ssh/id_rsa.pub |
があるかどうかチェック。無ければ以下のコマンド。
|
1 |
ssh-keygen -t rsa |
リモートログイン
Macの環境設定(system preference) > 共有(Sharing) > リモートログイン(Remote Login)を有効に。
SSH鍵認証
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
試しに、ssh loginを試みる
ssh localhost
exitでログアウト。
—————————————————————————-
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
MacBook-Pro-5: $ cd /opt/homebrew/Cellar/hadoop/3.3.1/ MacBook-Pro-5:$ ./bin/hdfs namenode -format MacBook-Pro-5:$ sudo chmod -R 777 /opt/homebrew/Cellar/hadoop/hdfs/tmp MacBook-Pro-5:$ ./sbin/start-dfs.sh Starting namenodes on [localhost] Starting datanodes Starting secondary namenodes [MacBook-Pro-5] MacBook-Pro-5:$ jps 1664 SecondaryNameNode 1509 DataNode 1403 NameNode 1755 Jps MacBook-Pro-5:$ ./sbin/start-yarn.sh Starting resourcemanager Starting nodemanagers MacBook-Pro-5:$ jps 1664 SecondaryNameNode 2083 Jps 1509 DataNode 2022 NodeManager 1403 NameNode 1903 ResourceManager |
———————————————-
JobTracker: http://localhost:8088
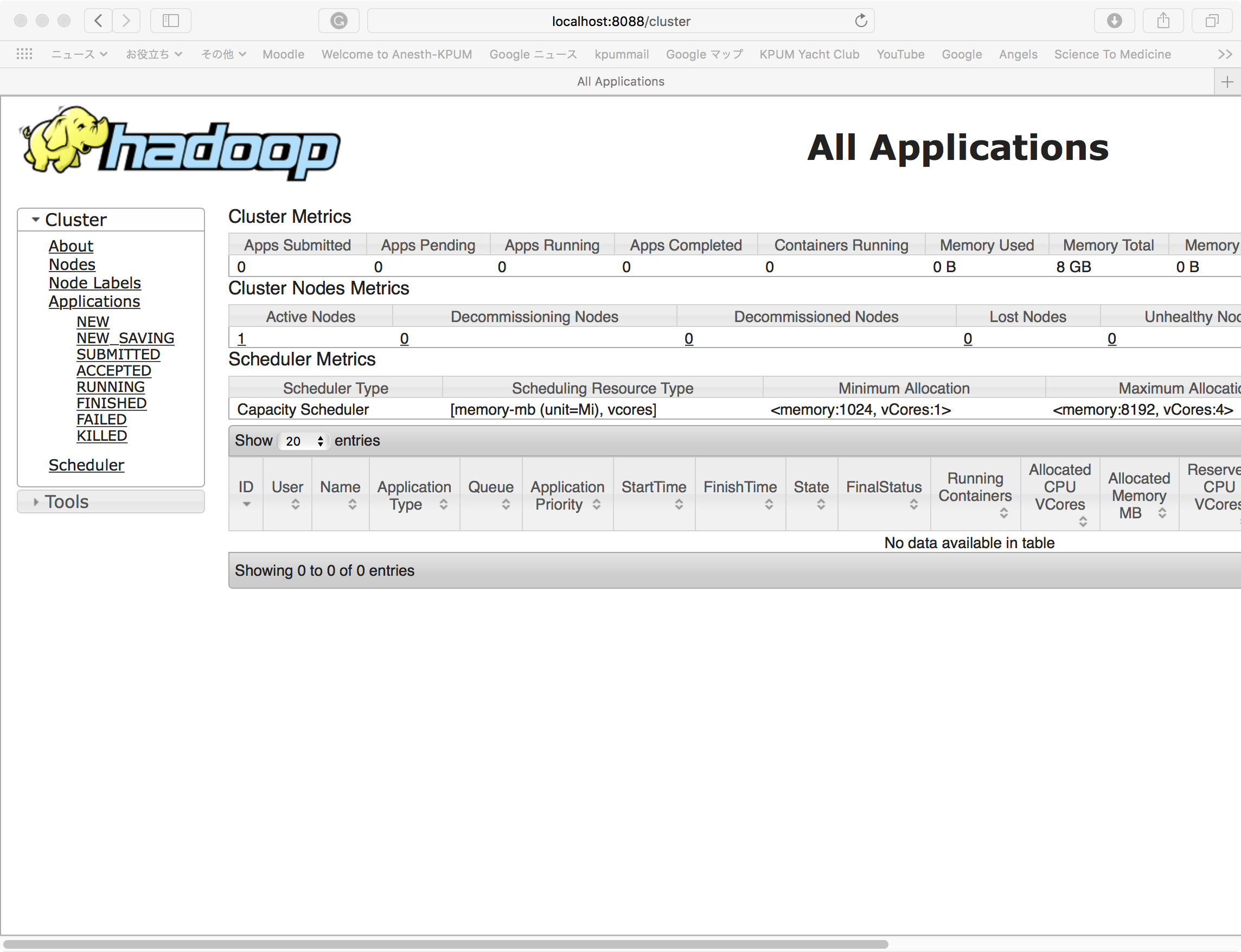
Hadoop Overview: http://localhost:9870
注意:Hadoop Overview http://localhost:50070は、上記のように変更になっている!
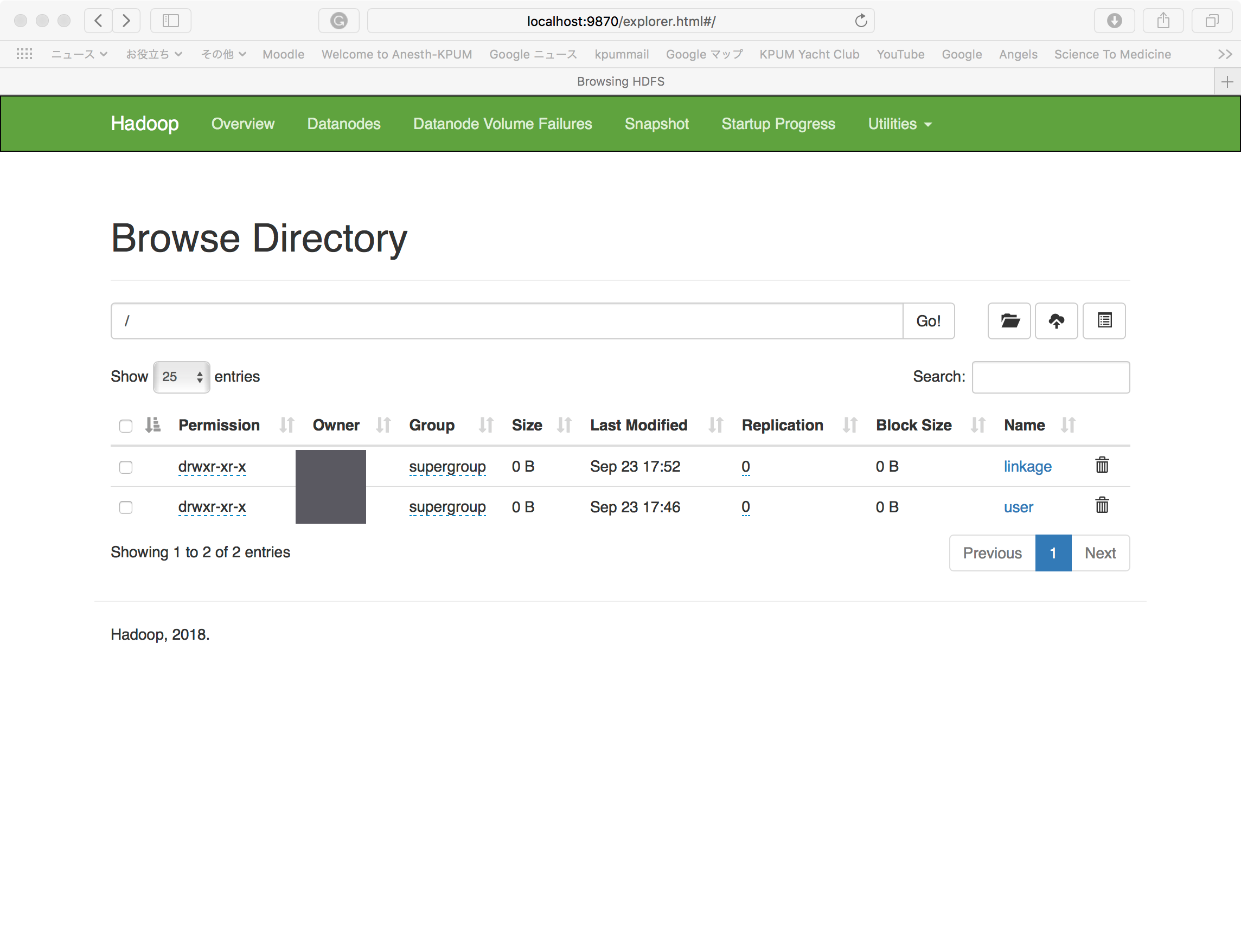
(注:linkageフォルダは次のプロセスでできたもの)
Specific Node Information: http://localhost:8042
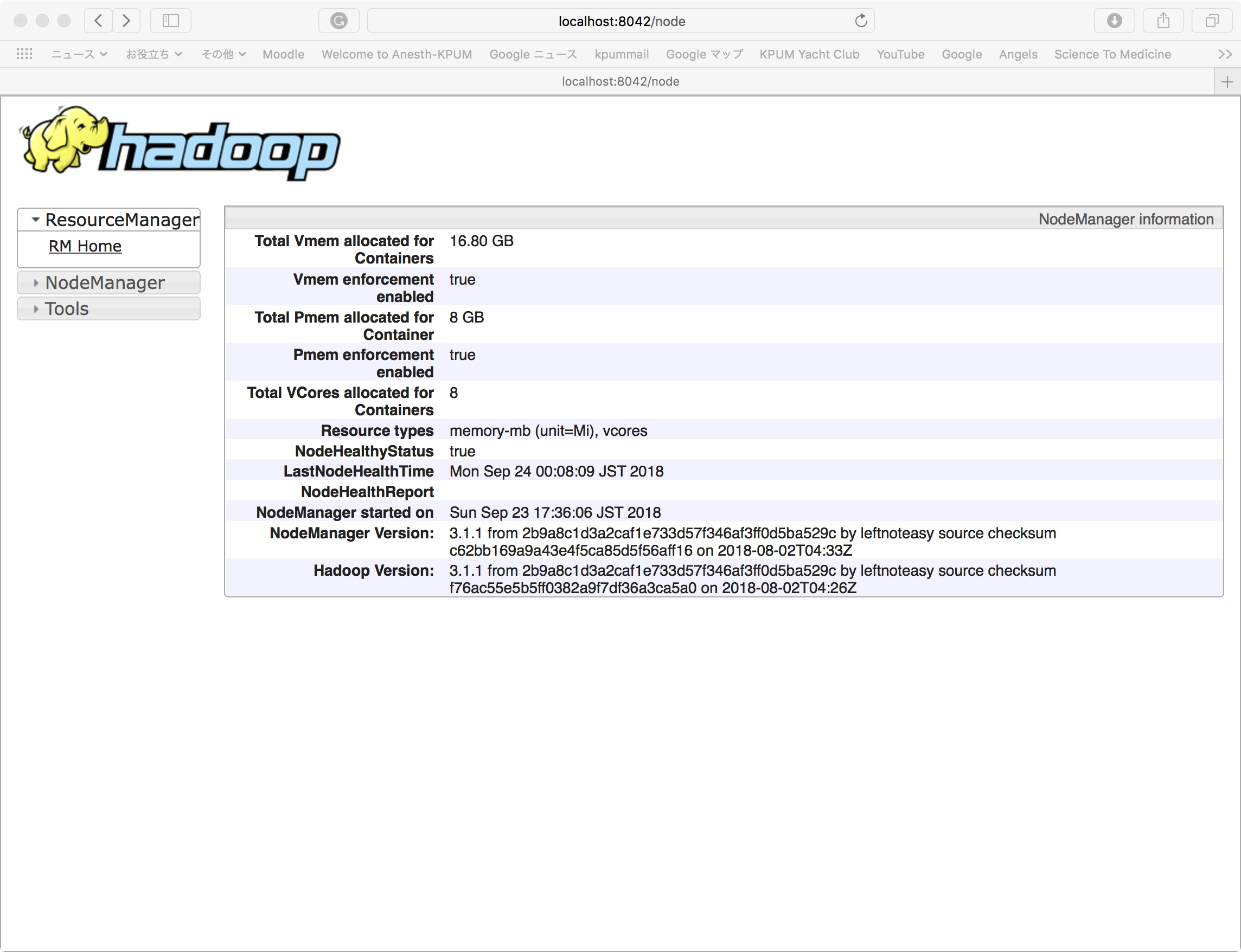
では、hdfsファイル構造を./bin/hadoop fs -****命令で以下のように操作していく。
何をしているかは、次のブログでまとめよう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
MacBook-Pro-5:sbin $ cd .. MacBook-Pro-5:3.1.1 $ cd bin MacBook-Pro-5:bin $ ./hadoop fs -ls / MacBook-Pro-5:bin $ ./hadoop fs -mkdir /linkage MacBook-Pro-5:bin $ ./hadoop fs -ls / Found 1 items drwxr-xr-x - ******* supergroup 0 2018-09-23 17:37 /linkage MacBook-Pro-5:3.1.1 $ ./hadoop fs -put /Users/******/linkage/block_*.csv /linkage MacBook-Pro-5:3.1.1 ******* $ ./hadoop fs -ls /linkage Found 12 items -rw-r--r-- 3 ******* supergroup 16 2018-09-23 17:38 /linkage/a.txt -rw-r--r-- 3 ******* supergroup 15 2018-09-23 17:39 /linkage/b.txt -rw-r--r-- 3 ******* supergroup 26248574 2018-09-23 17:52 /linkage/block_1.csv -rw-r--r-- 3 ******* supergroup 26255957 2018-09-23 17:52 /linkage/block_10.csv -rw-r--r-- 3 ******* supergroup 26241784 2018-09-23 17:52 /linkage/block_2.csv -rw-r--r-- 3 ******* supergroup 26253247 2018-09-23 17:52 /linkage/block_3.csv -rw-r--r-- 3 ******* supergroup 26247471 2018-09-23 17:52 /linkage/block_4.csv -rw-r--r-- 3 ******* supergroup 26249424 2018-09-23 17:52 /linkage/block_5.csv -rw-r--r-- 3 ******* supergroup 26256126 2018-09-23 17:52 /linkage/block_6.csv -rw-r--r-- 3 ******* supergroup 26261911 2018-09-23 17:52 /linkage/block_7.csv -rw-r--r-- 3 ******* supergroup 26253911 2018-09-23 17:52 /linkage/block_8.csv -rw-r--r-- 3 ******* supergroup 26254012 2018-09-23 17:52 /linkage/block_9.csv |