Scala@Spark を以下のサイトを参考に試してみる。
http://www.atmarkit.co.jp/ait/articles/1608/24/news014.html
/opt/spark-2.3.1-bin-hadoop2.7 にインストールしたsparkに対して、ターミナルから、spark-masterを立ち上げる。
|
1 2 |
MacBook-Pro-5:spark-2.3.1-bin-hadoop2.7 $ ./sbin/start-master.sh starting org.apache.spark.deploy.master.Master, logging to /opt/spark-2.3.1-bin-hadoop2.7/logs/spark-*******-org.apache.spark.deploy.master.Master-1-MacBook-Pro-5.local.out |
http://localhost:8080/でSpark WebUIにアクセスしてみると、

と無事に立ち上がっている。
続けて、spark-slaveを立ち上げてみる。
|
1 2 |
MacBook-Pro-5:spark-2.3.1-bin-hadoop2.7 $ ./sbin/start-slave.sh spark://MacBook-Pro-5.local:7077 starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-2.3.1-bin-hadoop2.7/logs/spark-*******-org.apache.spark.deploy.worker.Worker-1-MacBook-Pro-5.local.out |
するとWebUIにもスレーブが立ち上がったことが以下のように確認できる。
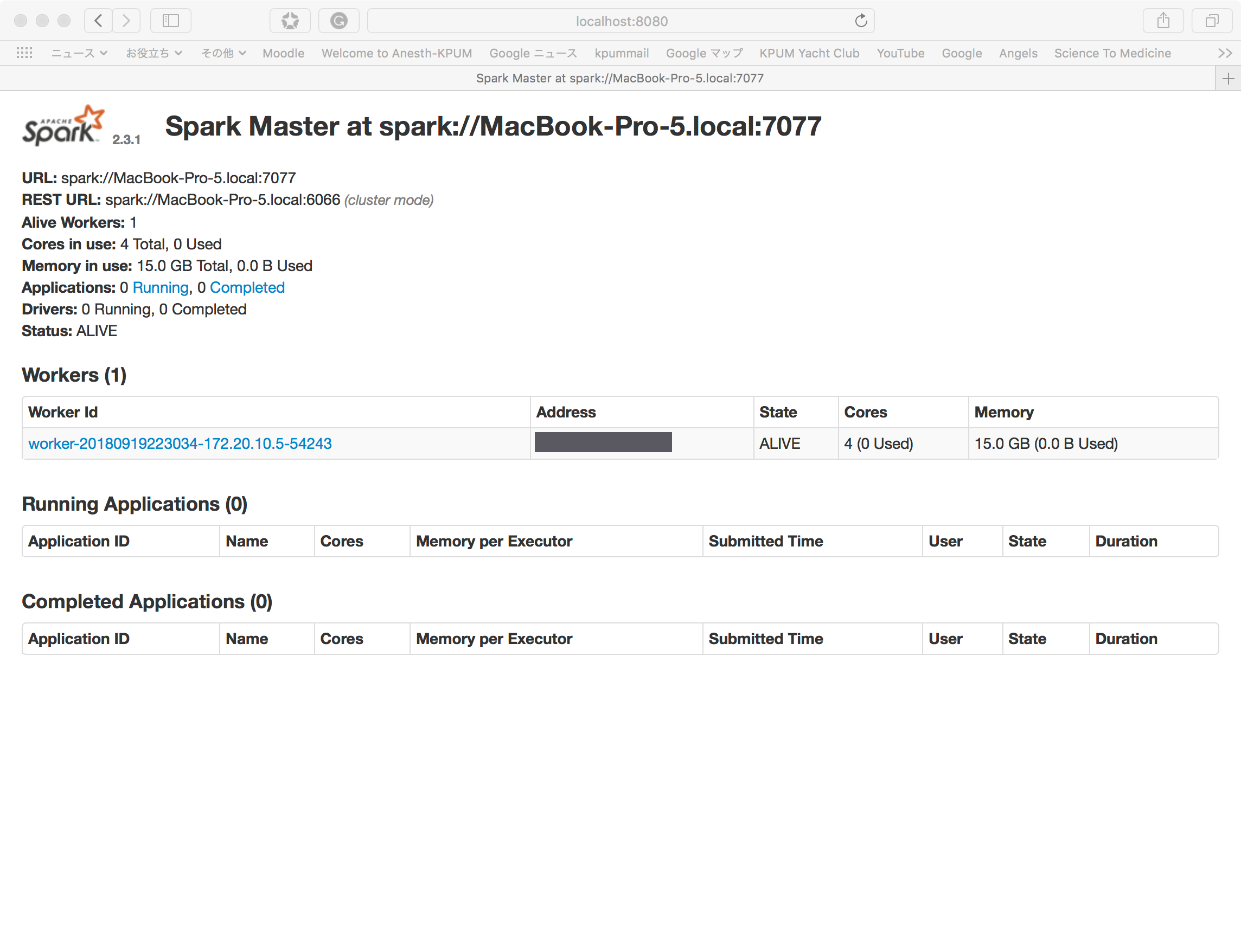
次に、Spark Shellで立ち上げたクラスタに接続する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
MacBook-Pro-5:spark-2.3.1-bin-hadoop2.7 $ ./bin/spark-shell --master spark://MacBook-Pro-5.local:7077 2018-09-19 22:33:33 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://********:4040 Spark context available as 'sc' (master = spark://MacBook-Pro-5.local:7077, app id = app-20180919223344-0000). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.3.1 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_131) Type in expressions to have them evaluated. Type :help for more information. scala> |
WebUIの「Running Applications」にNameが「Spark shell」となっている行が追加されている。
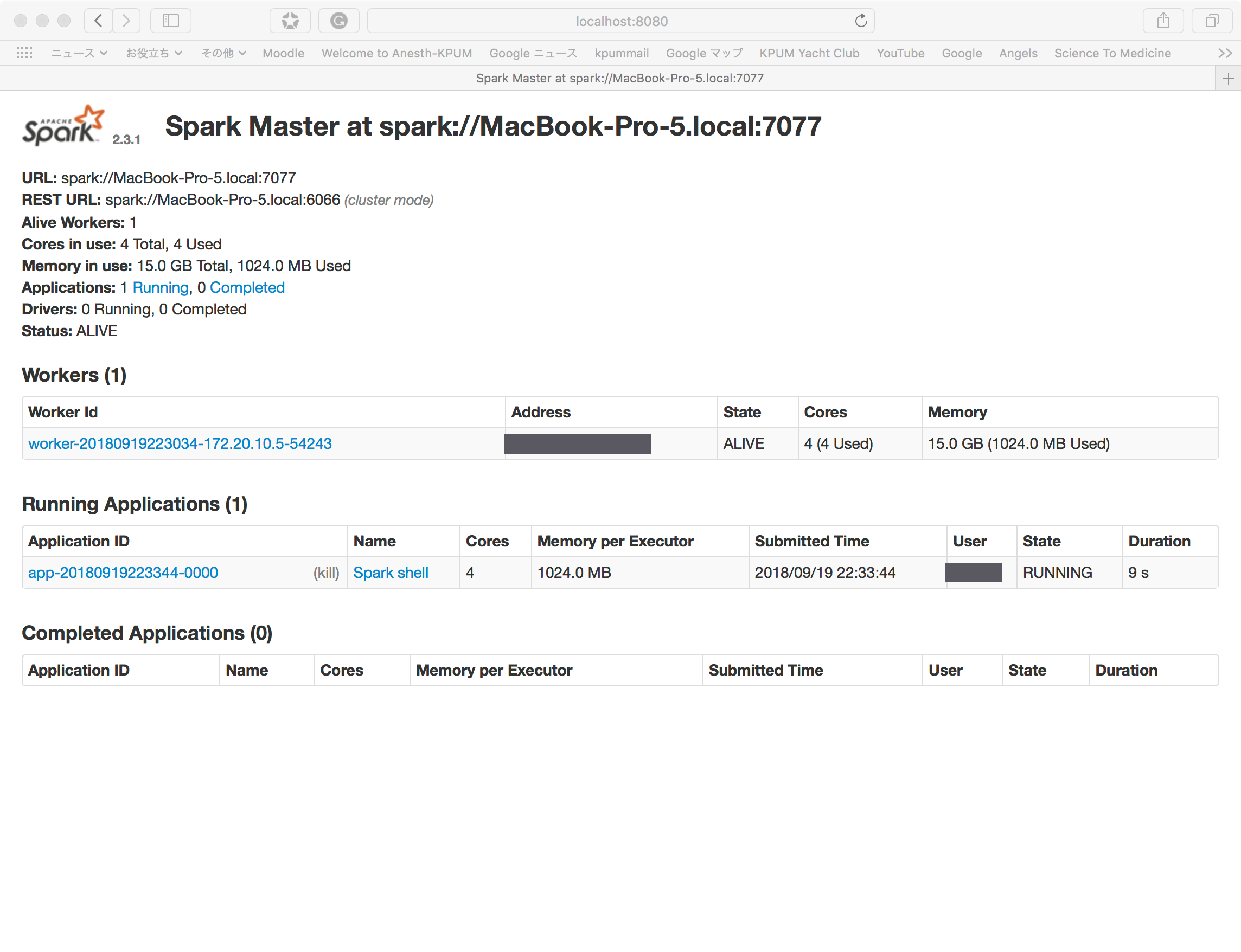
scala-shellで以下の計算を実行
|
1 2 3 4 5 |
scala> sc.parallelize(1 to 1000, 10).map(_*2).reduce(_+_) res0: Int = 1001000 scala> sc.parallelize(1 to 2147483647, 10).map(_.toDouble*2).reduce(_+_) res1: Double = 4.6116860143810673E18 |
WebUIで上記処理の状況を確認すると、39秒かかったことが理解できる。
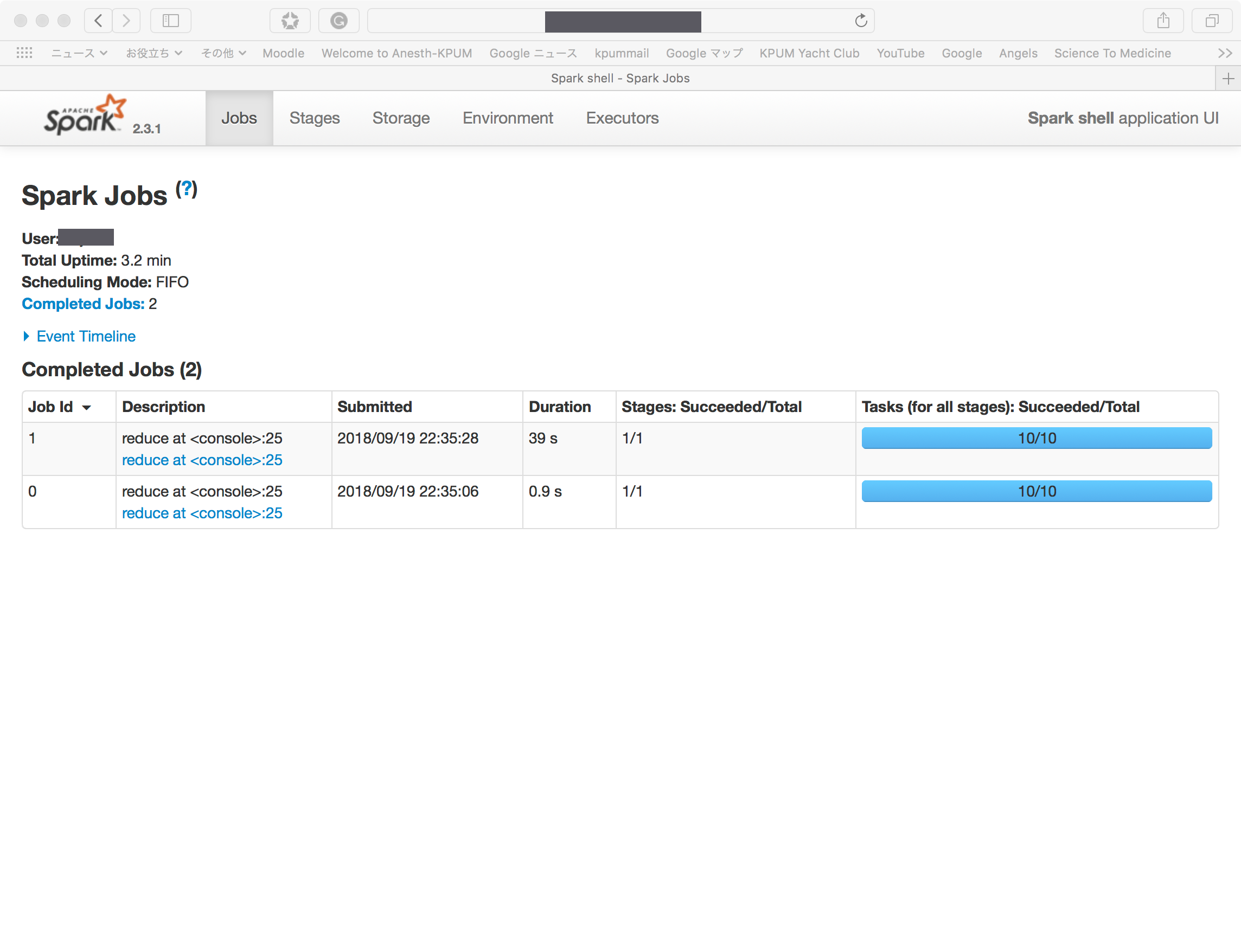
—————————————-
Sparkが何をどう扱うのか、概要がわかるだろう。
例えると、大量の「夏休みの宿題」を抱えて、一人で短期間で終了することができない状況で、
宿題を複数(RDD)に分割して、複数の頼める友達に頼む。友達は、「やり方がわからない」というので、自分(master)から、どうやったら済ませられるかの方法を各友達(slave)に教える。
うまくいくと、頼んだ人数分のスピードであっという間に宿題が終わる。ただし、自分(master)は、どの宿題を分割して誰に頼んだかとか、やり方について責任をもって管理しないと、とんでもないことになり得る。。。。。要するにこういう夏休み宿題の複数友達依頼作戦のようなものが、おそらくSparkの基本であろうことがおぼろげにも理解できた。