Mastering Machine Learning with Spark 2.xを学習する(続編)。Spark 2.3.1では、H2Oの導入で不具合発生!
Spark-2.1.1-bin-hadoop2.7に落として、再度Sparkling Waterの導入に挑戦する。

前回と同じく、ビルドしたmastering-ml-w-spark-utils_2.11-1.0.0_*jarファイルを3つを、sparkのlibsへコピーするとともに、.bash_profileに設定した、SPARK_HOMEをspark-2.1.1-bin-hadoop2.7とする。
|
1 2 |
MacBook-Pro-5:~ $ pico ./.bash_profile export SPARK_HOME=/opt/spark-2.1.1-bin-hadoop2.7 |
そして始めからやり直し。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 |
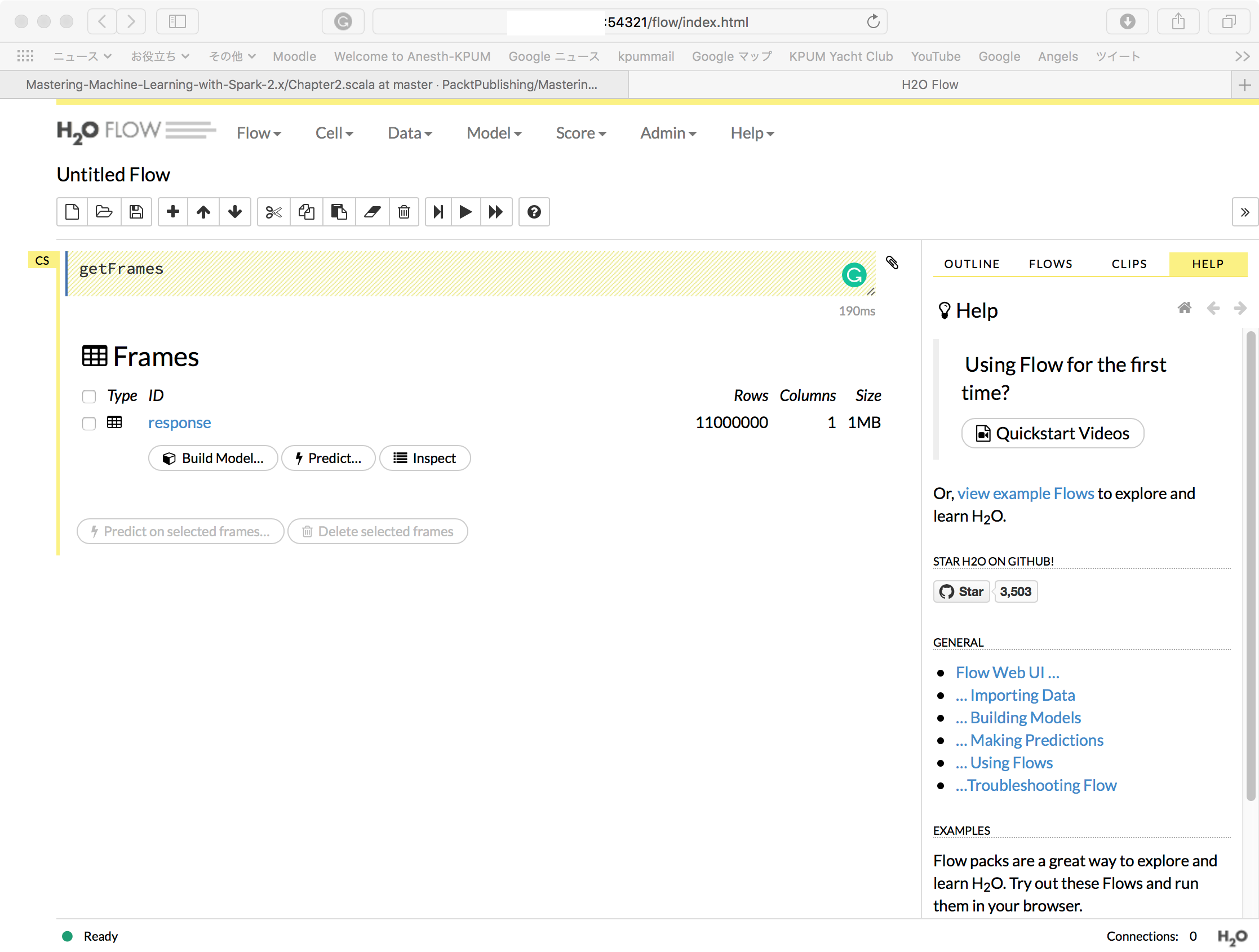
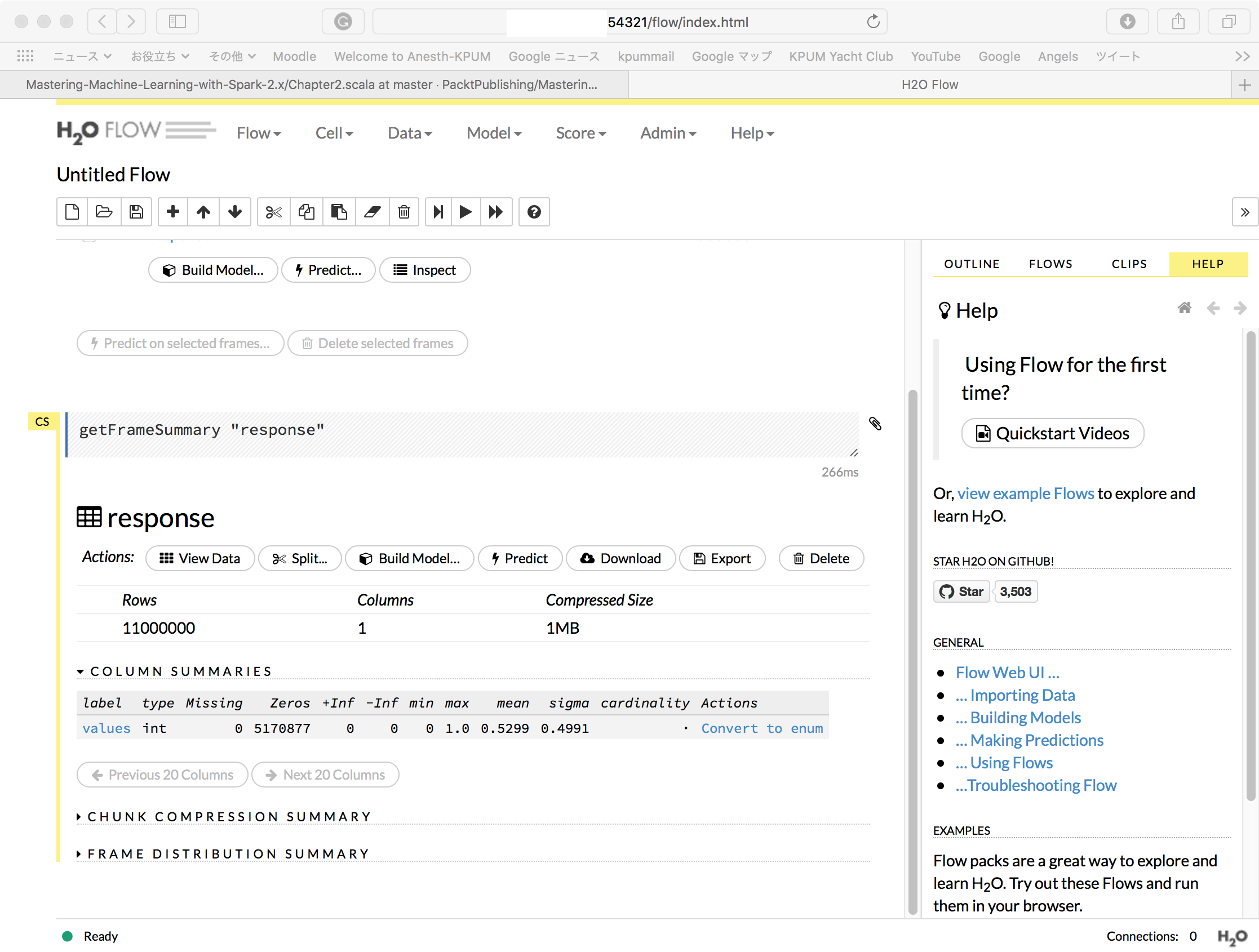
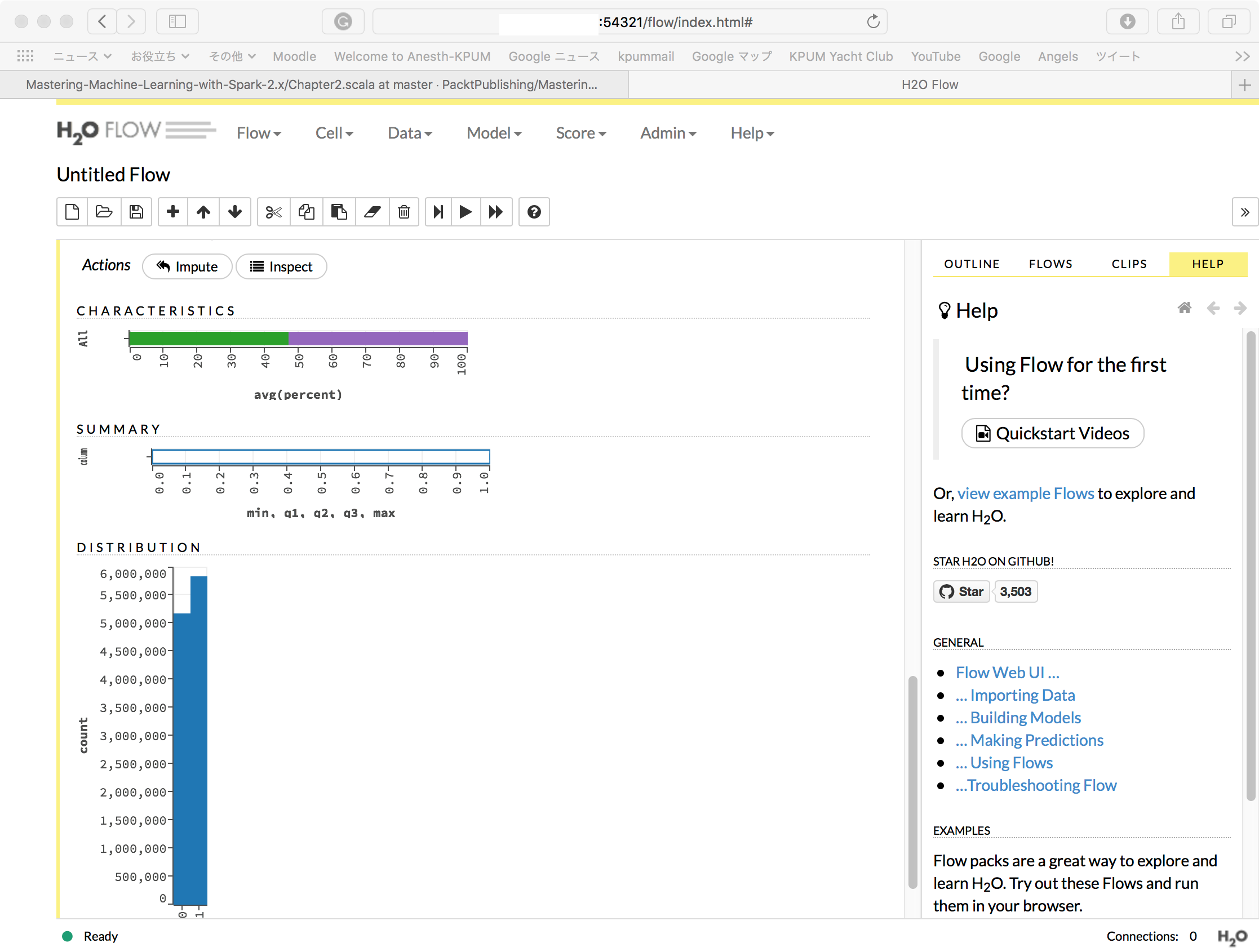
MacBook-Pro-5:~ $ export SPARKLING_WATER_VERSION="2.1.12" MacBook-Pro-5:~ $ export SPARK_PACKAGES="ai.h2o:sparkling-water-core_2.11:${SPARKLING_WATER_VERSION},\ > ai.h2o:sparkling-water-repl_2.11:${SPARKLING_WATER_VERSION},\ > ai.h2o:sparkling-water-ml_2.11:${SPARKLING_WATER_VERSION}" MacBook-Pro-5:~ $ ${SPARK_HOME}/bin/spark-shell --master local[*] --driver-memory 4g --executor-memory 4g --packages "$SPARK_PACKAGES" Ivy Default Cache set to: /Users/*******/.ivy2/cache The jars for the packages stored in: /Users/*******/.ivy2/jars :: loading settings :: url = jar:file:/opt/spark-2.1.1-bin-hadoop2.7/jars/ivy-2.4.0.jar!/org/apache/ivy/core/settings/ivysettings.xml ai.h2o#sparkling-water-core_2.11 added as a dependency ai.h2o#sparkling-water-repl_2.11 added as a dependency ai.h2o#sparkling-water-ml_2.11 added as a dependency :: resolving dependencies :: org.apache.spark#spark-submit-parent;1.0 confs: [default] ............. --------------------------------------------------------------------- | | modules || artifacts | | conf | number| search|dwnlded|evicted|| number|dwnlded| --------------------------------------------------------------------- | default | 77 | 0 | 0 | 11 || 62 | 0 | --------------------------------------------------------------------- :: retrieving :: org.apache.spark#spark-submit-parent confs: [default] 0 artifacts copied, 62 already retrieved (0kB/35ms) Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 18/10/22 10:44:07 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 18/10/22 10:44:16 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException Spark context Web UI available at http://***.***.***.***:4040 Spark context available as 'sc' (master = local[*], app id = local-1540172648705). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.1.1 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_181) Type in expressions to have them evaluated. Type :help for more information. scala> import org.apache.spark.rdd.RDD import org.apache.spark.rdd.RDD scala> import org.apache.spark.mllib.regression.LabeledPoint import org.apache.spark.mllib.regression.LabeledPoint scala> import org.apache.spark.mllib.linalg._ import org.apache.spark.mllib.linalg._ scala> import org.apache.spark.mllib.linalg.distributed.RowMatrix import org.apache.spark.mllib.linalg.distributed.RowMatrix scala> import org.apache.spark.mllib.evaluation._ import org.apache.spark.mllib.evaluation._ scala> import org.apache.spark.mllib.tree._ import org.apache.spark.mllib.tree._ scala> val rawData = sc.textFile("hdfs://localhost/user/*******/ds/HIGGS.csv") rawData: org.apache.spark.rdd.RDD[String] = hdfs://localhost/user/*******/ds/HIGGS.csv MapPartitionsRDD[3] at textFile at <console>:36 scala> println(s"Number of rows: ${rawData.count}") Number of rows: 11000000 scala> println("Rows") Rows scala> println(rawData.take(2).mkString("\n")) 1.000000000000000000e+00,8.692932128906250000e-01,-6.350818276405334473e-01,2.256902605295181274e-01,3.274700641632080078e-01,-6.899932026863098145e-01,7.542022466659545898e-01,-2.485731393098831177e-01,-1.092063903808593750e+00,0.000000000000000000e+00,1.374992132186889648e+00,-6.536741852760314941e-01,9.303491115570068359e-01,1.107436060905456543e+00,1.138904333114624023e+00,-1.578198313713073730e+00,-1.046985387802124023e+00,0.000000000000000000e+00,6.579295396804809570e-01,-1.045456994324922562e-02,-4.576716944575309753e-02,3.101961374282836914e+00,1.353760004043579102e+00,9.795631170272827148e-01,9.780761599540710449e-01,9.200048446655273438e-01,7.216574549674987793e-01,9.887509346008300781e-01,8.766783475875854492e-01 1.000000000000000000e+00,9.075421094894409180e-01,3.291472792625427246e-01,3.594118654727935791e-01,1.497969865798950195e+00,-3.130095303058624268e-01,1.095530629158020020e+00,-5.575249195098876953e-01,-1.588229775428771973e+00,2.173076152801513672e+00,8.125811815261840820e-01,-2.136419266462326050e-01,1.271014571189880371e+00,2.214872121810913086e+00,4.999939501285552979e-01,-1.261431813240051270e+00,7.321561574935913086e-01,0.000000000000000000e+00,3.987008929252624512e-01,-1.138930082321166992e+00,-8.191101951524615288e-04,0.000000000000000000e+00,3.022198975086212158e-01,8.330481648445129395e-01,9.856996536254882812e-01,9.780983924865722656e-01,7.797321677207946777e-01,9.923557639122009277e-01,7.983425855636596680e-01 scala> val data = rawData.map(line => line.split(',').map(_.toDouble)) data: org.apache.spark.rdd.RDD[Array[Double]] = MapPartitionsRDD[4] at map at <console>:38 scala> val response: RDD[Int] = data.map(row => row(0).toInt) response: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[5] at map at <console>:40 scala> val features: RDD[Vector] = data.map(line => Vectors.dense(line.slice(1, line.size))) features: org.apache.spark.rdd.RDD[org.apache.spark.mllib.linalg.Vector] = MapPartitionsRDD[6] at map at <console>:40 scala> val featuresMatrix = new RowMatrix(features) featuresMatrix: org.apache.spark.mllib.linalg.distributed.RowMatrix = org.apache.spark.mllib.linalg.distributed.RowMatrix@a55ed01 scala> val featuresSummary = featuresMatrix.computeColumnSummaryStatistics() featuresSummary: org.apache.spark.mllib.stat.MultivariateStatisticalSummary = org.apache.spark.mllib.stat.MultivariateOnlineSummarizer@56dde963 scala> import com.packtpub.mmlwspark.utils.Tabulizer.table import com.packtpub.mmlwspark.utils.Tabulizer.table scala> println(s"Higgs Features Mean Values = ${table(featuresSummary.mean, 8)}") Higgs Features Mean Values = +-----+------+------+------+-----+-----+------+-----+ |0.991|-0.000|-0.000| 0.999|0.000|0.991|-0.000|0.000| |1.000| 0.993|-0.000|-0.000|1.000|0.992| 0.000|0.000| |1.000| 0.986|-0.000| 0.000|1.000|1.034| 1.025|1.051| |1.010| 0.973| 1.033| 0.960| -| -| -| -| +-----+------+------+------+-----+-----+------+-----+ scala> println(s"Higgs Features Variance Values = ${table(featuresSummary.variance, 8)}") Higgs Features Variance Values = +-----+-----+-----+-----+-----+-----+-----+-----+ |0.320|1.018|1.013|0.360|1.013|0.226|1.019|1.012| |1.056|0.250|1.019|1.012|1.101|0.238|1.018|1.013| |1.425|0.256|1.015|1.013|1.961|0.455|0.145|0.027| |0.158|0.276|0.133|0.098| -| -| -| -| +-----+-----+-----+-----+-----+-----+-----+-----+ scala> val nonZeros = featuresSummary.numNonzeros nonZeros: org.apache.spark.mllib.linalg.Vector = [1.1E7,1.1E7,1.1E7,1.1E7,1.1E7,1.1E7,1.1E7,1.1E7,5605389.0,1.1E7,1.1E7,1.1E7,5476088.0,1.1E7,1.1E7,1.1E7,4734760.0,1.1E7,1.1E7,1.1E7,3869383.0,1.1E7,1.1E7,1.1E7,1.1E7,1.1E7,1.1E7,1.1E7] scala> println(s"Non-zero values count per column: ${table(nonZeros, cols = 8, format = "%.0f")}") Non-zero values count per column: +--------+--------+--------+--------+--------+--------+--------+--------+ |11000000|11000000|11000000|11000000|11000000|11000000|11000000|11000000| | 5605389|11000000|11000000|11000000| 5476088|11000000|11000000|11000000| | 4734760|11000000|11000000|11000000| 3869383|11000000|11000000|11000000| |11000000|11000000|11000000|11000000| -| -| -| -| +--------+--------+--------+--------+--------+--------+--------+--------+ scala> val numRows = featuresMatrix.numRows numRows: Long = 11000000 scala> val numCols = featuresMatrix.numCols numCols: Long = 28 scala> val colsWithZeros = nonZeros colsWithZeros: org.apache.spark.mllib.linalg.Vector = [1.1E7,1.1E7,1.1E7,1.1E7,1.1E7,1.1E7,1.1E7,1.1E7,5605389.0,1.1E7,1.1E7,1.1E7,5476088.0,1.1E7,1.1E7,1.1E7,4734760.0,1.1E7,1.1E7,1.1E7,3869383.0,1.1E7,1.1E7,1.1E7,1.1E7,1.1E7,1.1E7,1.1E7] scala> .toArray res7: Array[Double] = Array(1.1E7, 1.1E7, 1.1E7, 1.1E7, 1.1E7, 1.1E7, 1.1E7, 1.1E7, 5605389.0, 1.1E7, 1.1E7, 1.1E7, 5476088.0, 1.1E7, 1.1E7, 1.1E7, 4734760.0, 1.1E7, 1.1E7, 1.1E7, 3869383.0, 1.1E7, 1.1E7, 1.1E7, 1.1E7, 1.1E7, 1.1E7, 1.1E7) scala> .zipWithIndex res8: Array[(Double, Int)] = Array((1.1E7,0), (1.1E7,1), (1.1E7,2), (1.1E7,3), (1.1E7,4), (1.1E7,5), (1.1E7,6), (1.1E7,7), (5605389.0,8), (1.1E7,9), (1.1E7,10), (1.1E7,11), (5476088.0,12), (1.1E7,13), (1.1E7,14), (1.1E7,15), (4734760.0,16), (1.1E7,17), (1.1E7,18), (1.1E7,19), (3869383.0,20), (1.1E7,21), (1.1E7,22), (1.1E7,23), (1.1E7,24), (1.1E7,25), (1.1E7,26), (1.1E7,27)) scala> .filter { case (rows, idx) => rows != numRows } res9: Array[(Double, Int)] = Array((5605389.0,8), (5476088.0,12), (4734760.0,16), (3869383.0,20)) scala> val sparsity = nonZeros.toArray.sum / (numRows * numCols) sparsity: Double = 0.9210572077922078 scala> response.distinct.collect res10: Array[Int] = Array(0, 1) scala> response.map(v => (v,1)).countByKey res11: scala.collection.Map[Int,Long] = Map(0 -> 5170877, 1 -> 5829123) |
いよいよH2Oのライブラリーインポート
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
scala> import org.apache.spark.h2o._ import org.apache.spark.h2o._ scala> val h2oContext = H2OContext.getOrCreate(sc) 18/10/22 10:56:52 WARN H2OContext: Method H2OContext.getOrCreate with an argument of type SparkContext is deprecated and parameter of type SparkSession is preferred. ................ 10-22 10:56:59.307 172.16.125.115:54321 11860 main TRACE: H2OContext initialized h2oContext: org.apache.spark.h2o.H2OContext = Sparkling Water Context: * H2O name: sparkling-water-*******_local-1540172648705 * cluster size: 1 * list of used nodes: (executorId, host, port) ------------------------ (driver,***.**.***.***,54321) ------------------------ Open H2O Flow in browser: http://***.**.***.***:54321 (CMD + click in Mac OSX) scala> val h2oResponse = h2oContext.asH2OFrame(response, "response") 10-22 10:57:09.128 ***.**.***.***:54321 11860 main INFO: Locking cloud to new members, because water.Lockable h2oResponse: org.apache.spark.h2o.H2OFrame = Frame key: response cols: 1 rows: 11000000 chunks: 60 size: 1379214 scala> h2oContext.openFlow scala> 10-22 11:00:21.468 ***.**.***.***:54321 11860 #6473-182 INFO: GET /, parms: {} 10-22 11:00:21.512 ***.**.***.***:54321 11860 #6473-182 INFO: GET /flow/index.html, parms: {} 10-22 11:00:22.140 ***.**.***.***:54321 11860 #6473-182 INFO: GET /flow/index.html, parms: {} 10-22 11:00:22.149 ***.**.***.***:54321 11860 #6473-182 INFO: GET /3/Metadata/endpoints, parms: {} 10-22 11:00:22.555 ***.**.***.***:54321 11860 #6473-183 INFO: GET /3/NodePersistentStorage/categories/environment/names/clips/exists, parms: {} 10-22 11:00:22.555 ***.**.***.***:54321 11860 #6473-182 INFO: GET /3/NodePersistentStorage/notebook, parms: {} 10-22 11:00:22.556 ***.**.***.***:54321 11860 #6473-185 INFO: GET /3/About, parms: {} 10-22 11:00:22.556 ***.**.***.***:54321 11860 #6473-184 INFO: GET /flow/help/catalog.json, parms: {} 10-22 11:00:22.564 ***.**.***.***:54321 11860 #6473-186 INFO: GET /3/ModelBuilders, parms: {} 10-22 11:00:22.567 ***.**.***.***:54321 11860 #6473-187 INFO: POST /3/scalaint, parms: {} 10-22 11:00:22.641 ***.**.***.***:54321 11860 #6473-186 INFO: Found XGBoost backend with library: xgboost4j 10-22 11:00:23.351 ***.**.***.***:54321 11860 #6473-182 INFO: GET /flow/fonts/fontawesome-webfont.woff, parms: {v=4.2.0} |
H2O Flow UI登場!