台風24号ヒット! この莫大な破壊的エネルギーをプラス方向に利用できないのだろうか?
こちらはとにかくSparkするということで、Advanced Analytics from Spark第二章:交互最小二乗法を用いた協調フィルタリング:要するにrecommenderのアルゴリズム
—————————————————–
まずは、もととなるlast.fmの音楽情報ファイルのダウンロードと、HDFSへのコピー。
たいていリンクが壊れているのだが、幸い以下のサイトからデータファイルをダウンロード
http://www.iro.umontreal.ca/~lisa/datasets/profiledata_06-May-2005.tar.gz
必要なファイルは以下の3つ:
user_artist_data.txt 426.8M
artist_data.txt 56M
artist_alias.txt 2.9M
巨大なテキストファイル!
ファイルの内容は、README.txtによると
user_artist_data.txt
3 columns: userid artistid playcount
artist_data.txt
2 columns: artistid artist_name
artist_alias.txt
2 columns: badid, goodid
known incorrectly spelt artists and the correct artist id.
you can correct errors in user_artist_data as you read it in using this file
(we’re not yet finished merging this data)
user_artist_data.txtは、UserID ?tab ArtistID ?tab 再生回数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
1000002 1 55 1000002 1000006 33 1000002 1000007 8 1000002 1000009 144 1000002 1000010 314 1000002 1000013 8 1000002 1000014 42 1000002 1000017 69 1000002 1000024 329 1000002 1000025 1 1000002 1000028 17 1000002 1000031 47 1000002 1000033 15 ......... |
artist_data.txtは、ArtistID ?tab Artist名
|
1 2 3 4 5 6 7 8 9 10 |
1134999 06Crazy Life 6821360 Pang Nakarin 10113088 Terfel, Bartoli- Mozart: Don 10151459 The Flaming Sidebur 6826647 Bodenstandig 3000 10186265 Jota Quest e Ivete Sangalo 6828986 Toto_XX (1977 10236364 U.S Bombs - 1135000 artist formaly know as Mat ........ |
artisit_alias.txtには、どうやら同じアーティストの異なるIDの接続リストbadid, goodidのようだ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
1092764 1000311 1095122 1000557 6708070 1007267 10088054 1042317 1195917 1042317 1112006 1000557 1187350 1294511 1116694 1327092 6793225 1042317 1079959 1000557 6789612 1000591 1262241 1000591 .............. |
単純なデータだが、巨大なテキストファイルである。
この3つのテキストファイル、つまりユーザーがどのアーティストの曲を何回選択したかという単純な情報をもとに、機械学習をさせて、あるユーザーに推奨するアーティスト名を返すというコードを構築する。
Sparkの機械学ライブラリMLlibのAlternating Least Squares(ALS)を用いて構築するわけだが、
作業としては、artisit_alias.txtを用いて間違ったIDを正しいID(finalArtistID)に置き換えることと、ALSのアルゴリズムに放り込むために、Ratingオブジェクト(userID, finalArtistID, count)に変換する。かつ、Artist IDリストを放り込めば、アーティスト名が返されるようにしたいという訳。
————————————–
まずは、巨大なテキストファイルを、HadoopのHDFSに移す。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
MacBook-Pro-5:spark-2.3.1-bin-hadoop2.7 $ cd /usr/local/Cellar/hadoop/3.1.1/ MacBook-Pro-5:3.1.1 $ cd bin MacBook-Pro-5:bin $ ./hadoop fs -ls / Found 2 items drwxr-xr-x - ******* supergroup 0 2018-09-24 00:15 /linkage drwxr-xr-x - ******* supergroup 0 2018-09-23 17:46 /user MacBook-Pro-5:bin $ ./hadoop fs -cd user MacBook-Pro-5:bin $ ./hadoop fs -ls Found 1 items drwxr-xr-x - ******* supergroup 0 2018-09-23 17:46 output MacBook-Pro-5:bin $ ./hadoop fs -mkdir ds MacBook-Pro-5:bin $ ./hadoop fs -ls Found 2 items drwxr-xr-x - ******* supergroup 0 2018-09-29 14:48 ds drwxr-xr-x - ******* supergroup 0 2018-09-23 17:46 output MacBook-Pro-5:3.1.1 $ ./bin/hadoop fs -put /Users/*******/Desktop/profiledata_06-May-2005/artist_data.txt /user/*******/ds MacBook-Pro-5:3.1.1 $ ./bin/hadoop fs -put /Users/*******/Desktop/profiledata_06-May-2005/artist_alias.txt /user/*******/ds MacBook-Pro-5:3.1.1 $ ./bin/hadoop fs -put /Users/*******/Desktop/profiledata_06-May-2005/user_artist_data.txt /user/teijisw/ds |
http://localhost:9870/ でbrowseして転送されたか確かめると、
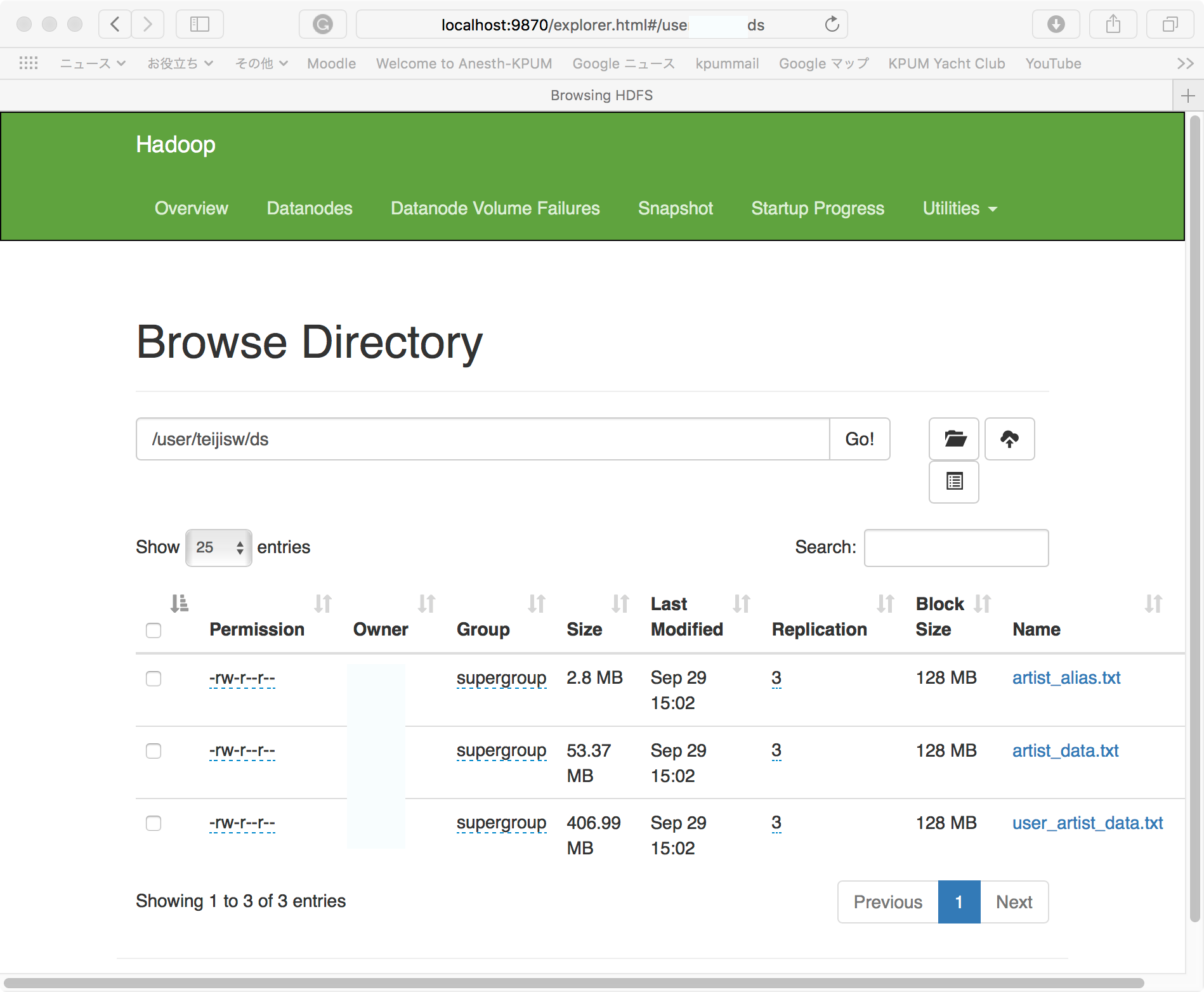
でOK。
では、Sparkの操作に移る。
大量のメモリが必要ということで、マルチコアモード&6G設定でspark-shellを立ち上げる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
MacBook-Pro-5:3.1.1 $ ${SPARK_HOME}/bin/spark-shell --master local[*] --driver-memory 6g 2018-09-29 15:17:03 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 2018-09-29 15:17:11 WARN Utils:66 - Service 'SparkUI' could not bind on port 4040. Attempting port 4041. Spark context Web UI available at http://macbook-pro-5:4041 Spark context available as 'sc' (master = local[*], app id = local-1538201831639). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.3.1 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_181) Type in expressions to have them evaluated. Type :help for more information. scala> |
まずは、データのRDDへの取り込み
|
1 2 3 4 5 |
scala> val rawUserArtistData = sc.textFile("hdfs://localhost/user/******/ds/user_artist_data.txt") rawUserArtistData: org.apache.spark.rdd.RDD[String] = hdfs://localhost/user/******/ds/user_artist_data.txt MapPartitionsRDD[3] at textFile at <console>:24 scala> rawUserArtistData.first res2: String = 1000002 1 55 |
UserIDやArtistIDについて統計を見ると、
|
1 2 3 4 5 |
scala> rawUserArtistData.map(_.split(' ')(0).toDouble).stats() res3: org.apache.spark.util.StatCounter = (count: 24296858, mean: 1947573.265353, stdev: 496000.544975, max: 2443548.000000, min: 90.000000) scala> rawUserArtistData.map(_.split(' ')(1).toDouble).stats() res4: org.apache.spark.util.StatCounter = (count: 24296858, mean: 1718704.093757, stdev: 2539389.040171, max: 10794401.000000, min: 1.000000) |
UserID最大値は、2,443,548件、Artist ID最大値は10,794,401
次にArtistIDを取り込む。
|
1 2 3 4 5 |
scala> val rawArtistData = sc.textFile("hdfs://localhost/user/*******/ds/artist_data.txt") rawArtistData: org.apache.spark.rdd.RDD[String] = hdfs://localhost/user/*******/ds/artist_data.txt MapPartitionsRDD[9] at textFile at <console>:24 scala> rawArtistData.first res5: String = 1134999 06Crazy Life |
アーティストIDとアーティスト名のリストを作成しておく:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
scala> val artistByID = rawArtistData.flatMap { line => | val (id, name) = line.span(_ != '\t') | if (name.isEmpty) { | None | } else { | try { | Some((id.toInt, name.trim)) | } catch { | case e: NumberFormatException => None | } | } | } artistByID: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[10] at flatMap at <console>:25 scala> artistByID.first res6: (Int, String) = (1134999,06Crazy Life) |
重複するアーティストIDについて、”正しい”IDに紐づけするMapを作成する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
scala> val artistAlias = rawArtistAlias.flatMap { line => | val tokens = line.split('\t') | if (tokens(0).isEmpty) { | None | } else { | Some((tokens(0).toInt, tokens(1).toInt)) | } | }.collectAsMap() artistAlias: scala.collection.Map[Int,Int] = Map(6803336 -> 1000010, 6663187 -> 1992, 2124273 -> 2814, 10412283 -> 1010353, 9969191 -> 1320354, 2024757 -> 1001941, 10208201 -> 4605, 2139121 -> 1011083, 1186393 -> 78, 2094504 -> 1012167, 9931106 -> 1000289, 2167517 -> 2060894, 1351735 -> 1266817, 6943682 -> 1003342, 2027368 -> 1000024, 2056419 -> 1020783, 1214789 -> 1001066, 1022944 -> 1004983, 6640739 -> 1010367, 6902331 -> 411, 10303141 -> 82, 10029249 -> 2070, 7001129 -> 739, 6627784 -> 1046699, 1113560 -> 1275800, 2155414 -> 1000790, 1291139 -> 4163, 10061700 -> 831, 1043158 -> 1301875, 10294241 -> 1234737, 9991298 -> 1001419, 9965450 -> 1016520, 6800447 -> 1078506, 1042440 -> 304, 1068288 -> 1001417, 6729982 -> 1809, 1138035 -> 1406, 1278247 -> 1239248, 1115453 -> 3824, 7035536 -> 3... scala> artistByID.lookup(6803336).head res7: String = Aerosmith (unplugged) scala> artistByID.lookup(1000010).head res8: String = Aerosmith |
ーーーーーーーーーーーーーーーーーーーーーー
次にモデル構築に先立って、Saprk MLlibのALSの実装での抽象化オブジェクトRatingを作成しておく。Ratingは(userID, finalID, count)という配列で構成される。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
scala> import org.apache.spark.mllib.recommendation._ import org.apache.spark.mllib.recommendation._ scala> val bArtistAlias = sc.broadcast(artistAlias) bArtistAlias: org.apache.spark.broadcast.Broadcast[scala.collection.Map[Int,Int]] = Broadcast(13) scala> val trainData = rawUserArtistData.map { line => | val Array(userID, artistID, count) = line.split(' ').map(_.toInt) | val finalArtistID = | bArtistAlias.value.getOrElse(artistID, artistID) | Rating(userID, finalArtistID, count) | }.cache() trainData: org.apache.spark.rdd.RDD[org.apache.spark.mllib.recommendation.Rating] = MapPartitionsRDD[20] at map at <console>:30 scala> trainData.first res16: org.apache.spark.mllib.recommendation.Rating = Rating(1000002,1,55.0) |
いよいよALSモデル構築:
|
1 2 3 4 5 6 7 8 9 |
scala> val model = ALS.trainImplicit(trainData, 10, 5, 0.01, 1.0) 2018-09-30 20:00:17 WARN BLAS:61 - Failed to load implementation from: com.github.fommil.netlib.NativeSystemBLAS 2018-09-30 20:00:17 WARN BLAS:61 - Failed to load implementation from: com.github.fommil.netlib.NativeRefBLAS [Stage 24:> (0 + 4) / 4]2018-09-30 20:00:19 WARN LAPACK:61 - Failed to load implementation from: com.github.fommil.netlib.NativeSystemLAPACK 2018-09-30 20:00:19 WARN LAPACK:61 - Failed to load implementation from: com.github.fommil.netlib.NativeRefLAPACK model: org.apache.spark.mllib.recommendation.MatrixFactorizationModel = org.apache.spark.mllib.recommendation.MatrixFactorizationModel@332d9d17 scala> model.userFeatures.mapValues(_.mkString(", ")).first() res10: (Int, String) = (116,-0.021858863532543182, -0.014364797621965408, 0.06130968779325485, -0.06215142086148262, -0.004167529288679361, 0.033082250505685806, 0.012420137412846088, 0.007236468605697155, 0.045138705521821976, -0.0030664762016385794) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
scala> val rawArtistsForUser = rawUserArtistData.map(_.split(' ')). | filter { case Array(user,_,_) => user.toInt == 2093760 } rawArtistsForUser: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[150] at filter at <console>:29 scala> val existingProducts = | rawArtistsForUser.map { case Array(_,artist,_) => artist.toInt }. | collect().toSet existingProducts: scala.collection.immutable.Set[Int] = Set(1255340, 942, 1180, 813, 378) scala> artistByID.filter { case (id, name) => | existingProducts.contains(id) | }.values.collect().foreach(println) David Gray Blackalicious Jurassic 5 The Saw Doctors Xzibit |
レコメンデーションを動かしてみると、
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
scala> recommendations.foreach(println) Rating(2093760,2814,0.028278282551135854) Rating(2093760,1300642,0.02794663060097468) Rating(2093760,1001819,0.027406245396385975) Rating(2093760,1007614,0.027003857902096893) Rating(2093760,4605,0.026823378469111325) scala> val recommendedProductIDs = recommendations.map(_.product).toSet recommendedProductIDs: scala.collection.immutable.Set[Int] = Set(2814, 1001819, 1300642, 4605, 1007614) scala> artistByID.filter { case (id, name) => | recommendedProductIDs.contains(id) | }.values.collect().foreach(println) 50 Cent Snoop Dogg Jay-Z 2Pac The Game |