Advanced Analytics from Spark、Oreillyから学習を開始する。
UCIのMachine Learning Repositoryの中から、2010年ドイツでの病院での600万人近い患者のマッチングデータに関する研究。名前や生年月日、郵便番号から同一患者かどうかを判定することに関してのデータ。
5,749,132件のレコードペアの中で、マッチしたのが20,931件で、データは以下の12項目で構成される。データセットは10ブロックに、均等なサイズ、均等なマッチ/アンマッチ比率に分けられて提供されている。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
1. id_1: Internal identifier of first record. 2. id_2: Internal identifier of second record. 3. cmp_fname_c1: agreement of first name, first component 4. cmp_fname_c2: agreement of first name, second component 5. cmp_lname_c1: agreement of family name, first component 6. cmp_lname_c2: agreement of family name, second component 7. cmp_sex: agreement sex 8. cmp_bd: agreement of date of birth, day component 9. cmp_bm: agreement of date of birth, month component 10. cmp_by: agreement of date of birth, year component 11. cmp_plz: agreement of postal code 12. is_match: matching status (TRUE for matches, FALSE for non-matches) |
|
1 |
curl -L -o donation.zip http://bit.ly/1Aoywaq |
からを利用したUCI Machine Learning Repositoryからはデータが取れなくなっているので、以下のUMASSのMirror siteから直接ダウンロードする。
http://mlr.cs.umass.edu/ml/machine-learning-databases/00210/
unzipを繰り返して、中身の10個のblock_*.csvだけを、新たに作成した~/linkageフォルダに収める。
block_1.csvをエディターで覗いてみると
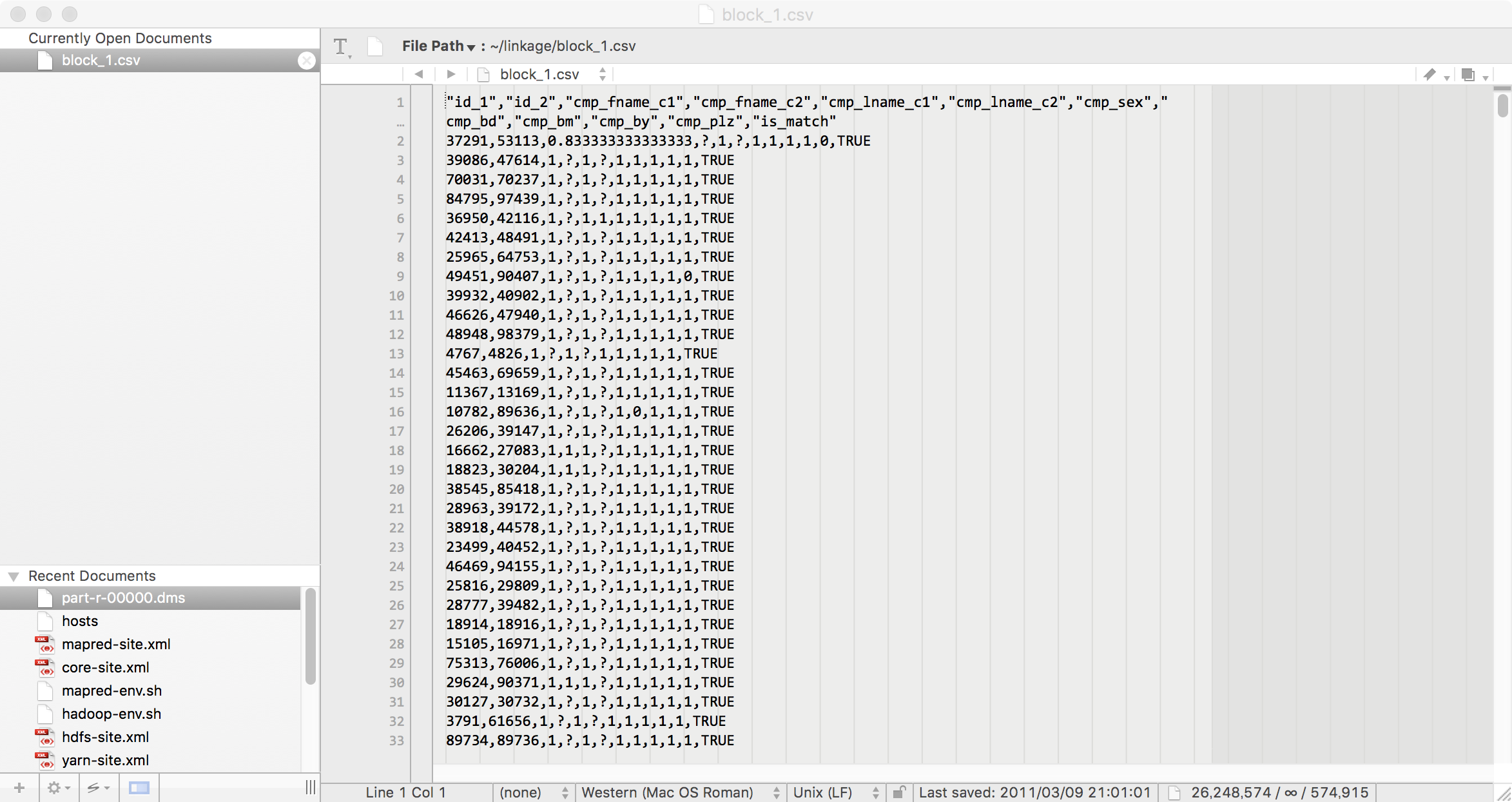
と57万5千件近いデータが一行づつ収まっている。
前回のブログで記述してしまっているが、この~/linkageフォルダに収めたcsvファイルを、HadoopのHDFSに収めることとする。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
MacBook-Pro-5: $ cd /usr/local/Cellar/hadoop/3.1.1/ MacBook-Pro-5:3.1.1 $ cd bin MacBook-Pro-5:bin $ ./hadoop namenode -format MacBook-Pro-5:bin $ cd .. MacBook-Pro-5:3.1.1 $ cd sbin MacBook-Pro-5:sbin $ ./start-dfs.sh Starting namenodes on [localhost] Starting datanodes Starting secondary namenodes [MacBook-Pro-5] MacBook-Pro-5:sbin $ jps 1664 SecondaryNameNode 1509 DataNode 1403 NameNode 1755 Jps MacBook-Pro-5:sbin $ ./start-yarn.sh Starting resourcemanager Starting nodemanagers MacBook-Pro-5:sbin $ jps 1664 SecondaryNameNode 2083 Jps 1509 DataNode 2022 NodeManager 1403 NameNode 1903 ResourceManager MacBook-Pro-5:sbin $ cd .. MacBook-Pro-5:3.1.1 $ cd bin MacBook-Pro-5:bin $ ./hadoop fs -ls / MacBook-Pro-5:bin $ ./hadoop fs -mkdir /linkage MacBook-Pro-5:bin $ ./hadoop fs -ls / Found 1 items drwxr-xr-x - ******* supergroup 0 2018-09-23 17:37 /linkage MacBook-Pro-5:3.1.1 $ ./bin/hadoop fs -mkdir /linkage MacBook-Pro-5:3.1.1 $ ./bin/hadoop fs -ls / Found 1 items drwxr-xr-x - ******* supergroup 0 2018-09-23 17:38 /linkage MacBook-Pro-5:3.1.1 $ ./bin/hadoop fs -put /Users/******/linkage/block_*.csv /linkage MacBook-Pro-5:3.1.1 $ ./bin/hadoop fs -ls /user/*******/ drwxr-xr-x - ******* supergroup 0 2018-09-23 17:46 /user/******** MacBook-Pro-5:3.1.1 ******* $ ./bin/hadoop fs -ls /linkage Found 10 items -rw-r--r-- 3 ******* supergroup 26248574 2018-09-23 17:52 /linkage/block_1.csv -rw-r--r-- 3 ******* supergroup 26255957 2018-09-23 17:52 /linkage/block_10.csv -rw-r--r-- 3 ******* supergroup 26241784 2018-09-23 17:52 /linkage/block_2.csv -rw-r--r-- 3 ******* supergroup 26253247 2018-09-23 17:52 /linkage/block_3.csv -rw-r--r-- 3 ******* supergroup 26247471 2018-09-23 17:52 /linkage/block_4.csv -rw-r--r-- 3 ******* supergroup 26249424 2018-09-23 17:52 /linkage/block_5.csv -rw-r--r-- 3 ******* supergroup 26256126 2018-09-23 17:52 /linkage/block_6.csv -rw-r--r-- 3 ******* supergroup 26261911 2018-09-23 17:52 /linkage/block_7.csv -rw-r--r-- 3 ******* supergroup 26253911 2018-09-23 17:52 /linkage/block_8.csv -rw-r--r-- 3 ******* supergroup 26254012 2018-09-23 17:52 /linkage/block_9.csv |
localhost:9870のUtilitiesのBrowse DirectoryでHDSFにデータファイルが、コピーされたことが確認できる。
http://localhost:9870/explorer.html#/
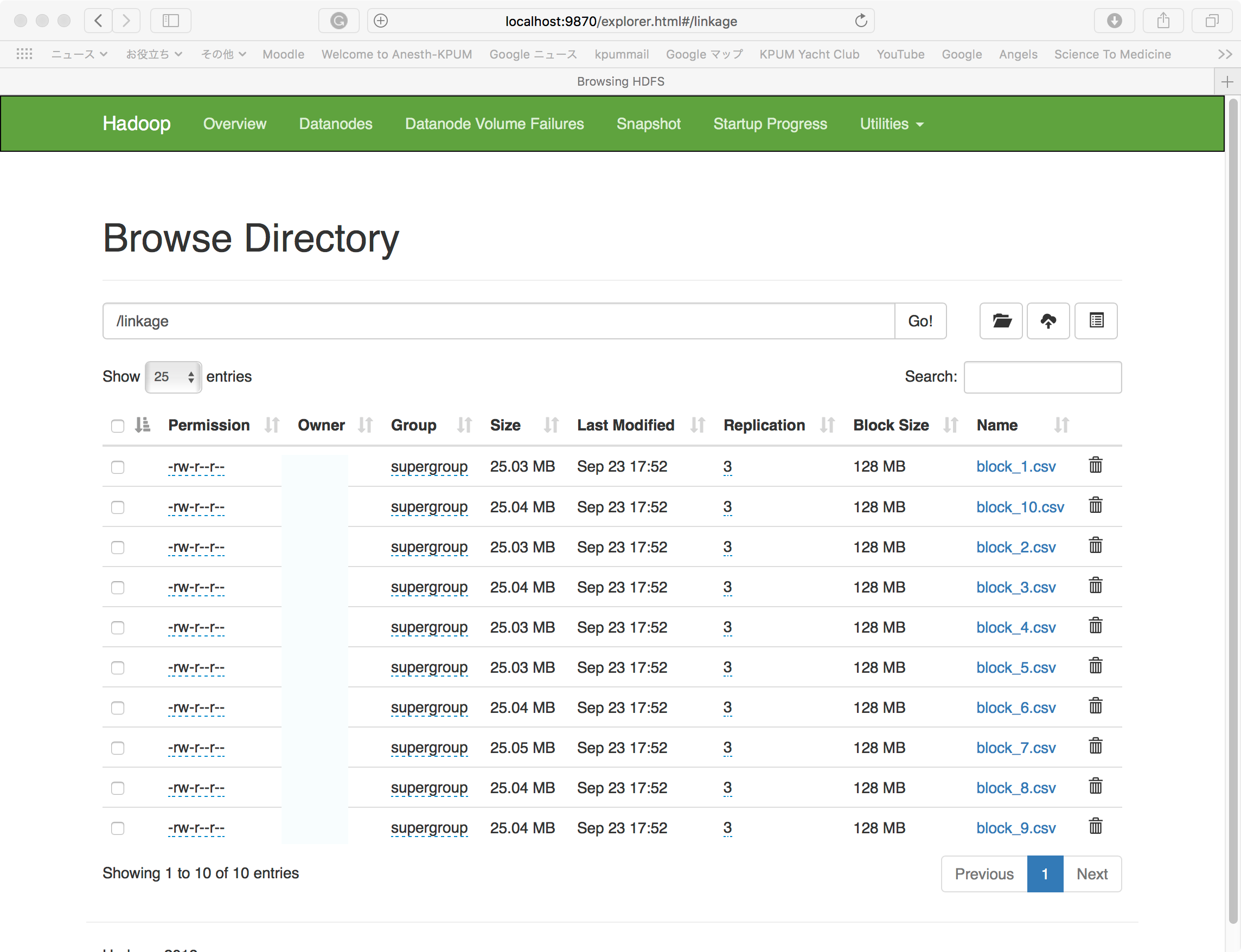
ではいよいよ、Spark-Shellをローカルモードで起動する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
MacBook-Pro-5:spark-2.3.1-bin-hadoop2.7 $ ${SPARK_HOME}/bin/spark-shell --master local 2018-09-24 00:16:10 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://macbook-pro-5:4040 Spark context available as 'sc' (master = local, app id = local-1537715778850). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.3.1 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_181) Type in expressions to have them evaluated. Type :help for more information. scala> |